
年別や地域別で複数のデータセットにまたがったデータを一つに解析用に連結します。 更に、連結した際のお作法として重複した行があれば削除します。
チートシート
| やりたいこと | コーディング |
|---|---|
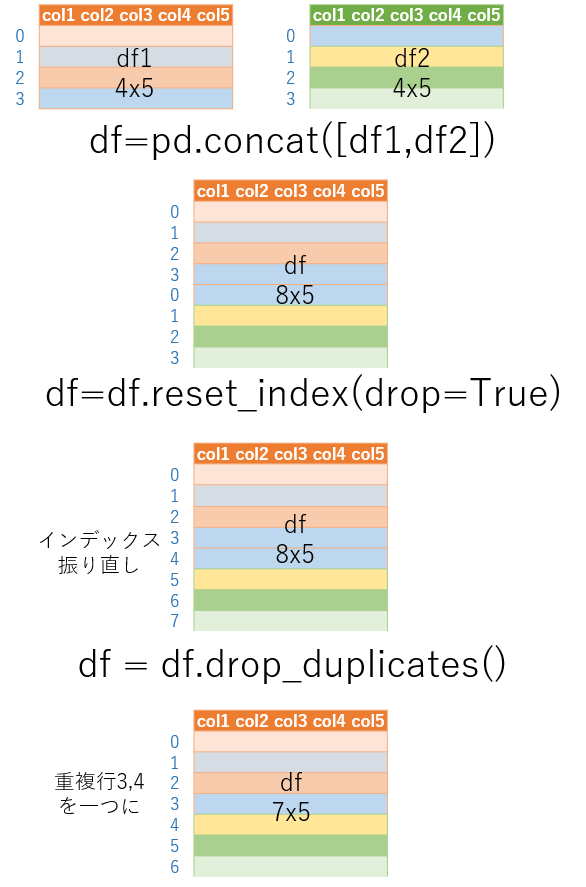
| 複数のデータフレームの行を連結する | df = pd.concat([df1, df2]) |
| 新しくインデックスをつけ直し、元のインデックスは削除する | df.reset_index(drop=True) |
| 重複した行を削除する | df = df.drop_diplicates() |
概念図
今回のデータ操作の流れは以下のとおりです。
ポイント
- df1 にdf2の行を追加する
- 列名の行は追加されない
- インデックスはそのままなので、重複するため振り直す
df.reset_index(drop=True)と指定しないと元のインデックスが列として残る- 念の為、重複した行があれば削除する
Kaggle データ
今回は、いつものデータフレームではなく、Kaggle よりHRデータ をダウンロードしてオペレーションしました。 欠損値のチェックやデータセットの理解のための一連の作業は実施済です。
サンプルデータセットについてにデータセットの概要があります。参考にしてください。
1
2
3
4
5
# データを分割して作成したdf1 とdf2 を連結する
print('before df1', df1.shape)
print('before df2', df2.shape)
df=pd.concat([df1,df2])
print('after df', df.shape)
結果は以下のとおりです。
before df1 (10, 35)
before df2 (30, 35)
after df (40, 35)2つのデータフレームとも同じ行数です。次に、ダミー変数のデータフレームのtdfkをdf に連結します。 今回の連結には pd,concat メソッドでdf にtdfk を追加する感じで連結します。 また、都道府県番号が入った’PY_07’は必要ないので、ドロップしてます。
1
2
# インデックスを振り直します
df =df.reset_index(drop=True)
1
2
3
4
# 重複した行を除外します
print('before', df.shape)
df = df.drop_duplicates()
print('after', df.shape)
df のサイズを確認します。ちなみに、df=df.drop_duplicates() と同じdf に代入しているため、行数が変化します。
df.drop_duplicates(inplace=True) とinplace=Trueを指定するとdfに代入する必要はありません。
before (40, 35)
after (32, 35)Kaggle データで行ってみる
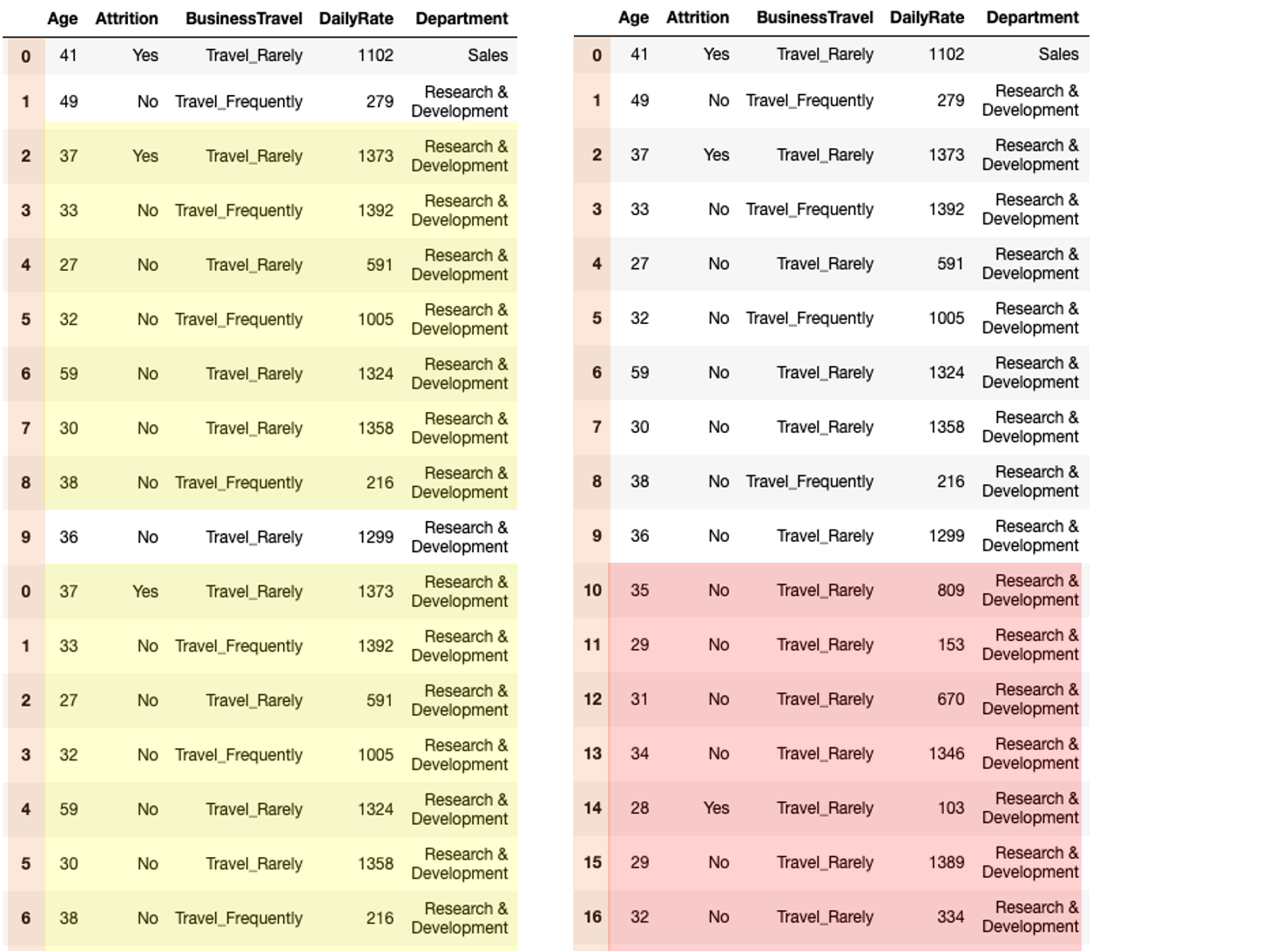
Kaggle よりHRデータ で2つのデータフレームを作成して上記の一連の操作を行いました。
データフレームのビフォア、アフターは以下のようになりました。 薄いオレンジがインデクスです。 薄黄色が重複のある行です。 それが除外され、赤い部分に置き換わっています。
ひとこと
マシンラーニング等で解析する場合は、一つの大きなデータセットをトレーニングとテストに分けていきます。 人が解析や管理するには、データセットを細分化した方が都合がいいかもしれません。 そのため、解析にあたりこのような単純ではあるが、気の抜けない「結合作業」は必ず存在します。
参照ページ一覧
このブログを作成するにあたり、以下のページを参考にしています。併せてご覧ください。
1) データセットの結合 pd.concat 縦向き、横向き結合
2) Merge Join Concat Dataframes
3) データセットの結合 pd.merge 左、右、外部、内部、クロス結合