
DataFrameまたは名前付きSeriesオブジェクトをデータベーススタイルの結合で結合する pd.mergeについてまとました。
結合(pd.merge)は列またはインデックスを共通の軸にして行われます。列同士で結合する場合、DataFrameのインデックスは無視されます。一方、インデックス同士で結合するか、インデックスを列と結合する場合、インデックスは引き継がれます。ちょっとややこしい pd.merge のルールをできるだけわかりやすくまとめてみました。
pd.merge のルール
- DataFrame(DataFrame)または名前付きシリーズ(Series)オブジェクト*をデータベーススタイルの結合で結合します。
- データベーススタイルの結合とは、SQLの左、右、フル外部結合、内部結合に類似した結合です。
- 名前付きSeriesオブジェクトは、単一の名前付き列を持つDataFrameとして扱われます。
- 結合は列またはインデックスで行われます。
- 列を列で結合する場合、DataFrameのインデックスは無視されます。
- 一方、インデックスをインデックスで結合するか、インデックスを列に結合する場合、インデックスは引き継がれます。
- クロス結合を行う際には、結合対象の列の指定は許可されません。
- 名前付きSeriesオブジェクトでの結合はこのブログでは扱いません。すべて、DataFrameを前提にしています。
参照: pd.merge
結合のスタイル(how = ‘引数’)
結合のスタイルを表でまとめてみました。
| 種類 | 内容 |
|---|---|
| left(左) | 左のDataFrameからのキーのみを使用し、SQLの左外部結合に類似します。キーの順序を保持します。 |
| right(右) | 右のDataFrameからのキーのみを使用し、SQLの右外部結合に類似します。キーの順序を保持します。 |
| outer(外部) | 両方のDataFrameからのキーの和集合を使用し、SQLのフル外部結合に類似します。キーを辞書式に並べ替えます。 |
| inner(内部) | 両方のDataFrameからのキーの共通部分を使用し、SQLの内部結合に類似します。左側のキーの順序を保持します。 |
| cross(クロス) | 両方のDataFrameからのデータの直積を作成し、左側のキーの順序を保持します。 |
pd.merge のコーディングルール
コーディングルールは以下のとおりです。pd.mergeのとおり、引数は他にもありますので、興味がある方は、参照すると良いでしょう。 df1 が左(left)、 df2 が右(right) です。

サンプルデータフレームの作成
各々の結合スタイルを例示するため、
サンプルDataFrame, df1 と df2 を以下のように作成すます。
また、サンプルではインデックスを軸に結合するため、set_index('インデックスにしたい列名') で明示的にインデックスを指定しています。 また、元に戻す場合は、reset_index()で戻ります。
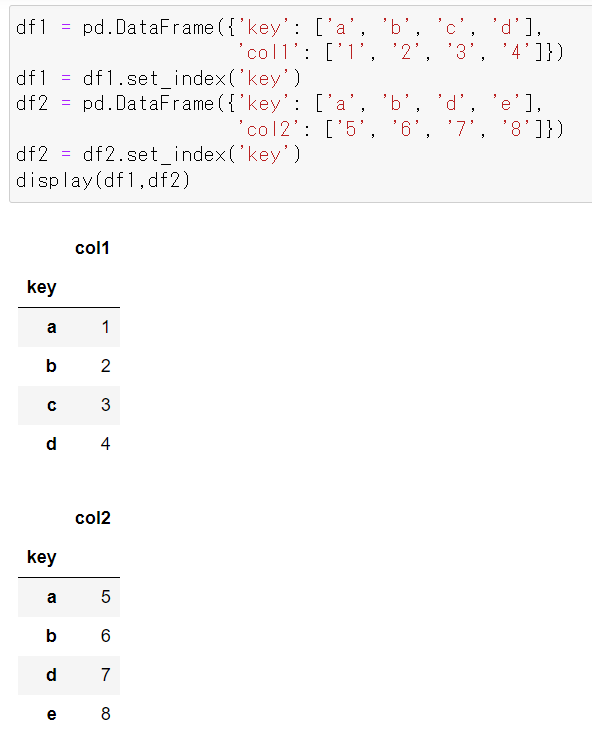
左結合
左のDataFrame df1のインデックス[a, b, c, d]を軸にdf1のcol1にdf2のcol2が, col1,col2の順序で結合されます。インデックス値の順序は変わりません。 df2のインデックスにはc がありませんので、col2 の値にはNaNが代入されます。
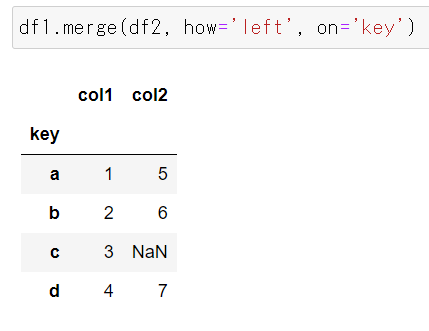
右結合
右のDataFrame df2のインデックス[a, b, d, e]を軸にdf1のcol1にdf2のcol2がcol1,col2の順序で結合されます。インデックス値の順序は変わりません。 df1のインデックスにはe がありませんので、col1の値にはNaNが代入されます。 当たり前ですが、df1 のインデックス値cは対象となりません。
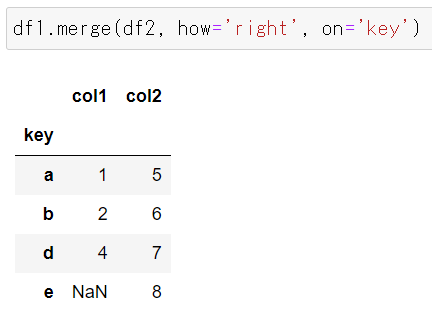
外部結合
df1のインデックス[a, b, c, d]とdf2のインデックス[a, b, d, e]の和集合のインデックス値[a, b, c, d, e]を軸にdf1のcol1にdf2のcol2が結合されます。インデックスの順序はa,b,c順です。
df1のインデックスにはe がdf2のインデックス値cがありませんので、それらはそれぞれNaNが代入されます。

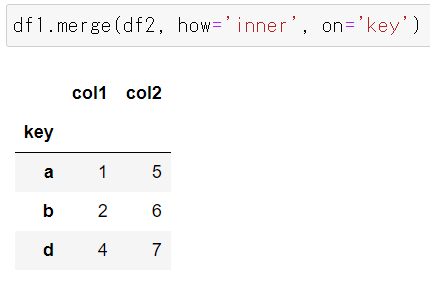
内部結合
df1のインデックス[a, b, c, d]とf2のインデックス[a, b, d, e]の積集合のインデックス値[a, b, d, ]を軸にdf1 にdf2 が結合されます。
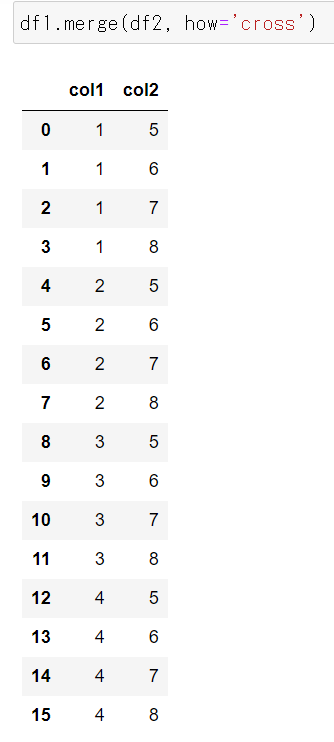
クロス結合
クロス結合(cross join)は、2つのDataFrameの全ての行同士の組み合わせを生成する操作です。クロス結合は、結合する列(キー)を指定せずに、単に2つのDataFrameを結合し、結果として全ての行の組み合わせを生成します。
クロス結合は通常、大きなデータセットの場合や特定の条件を満たす全ての組み合わせを見つける必要がある場合に使用されます。ただし、DataFrameが大きい場合は生成される組み合わせが爆発的に増加し、メモリ使用量が増加する可能性があるため、注意が必要です。
チートシート
| やりたいこと | コーディング |
|---|---|
| ‘キー列名 key’でdf1にdf2を左結合する | df1.merge(df2, how=’left’, on =’キー列名 key’) |
列名 keyをデータフレームdfのインデックスにする |
df.set_index(‘列名 key’) |
データフレームdfのインデックスを0,1,2.. に戻す |
df.reset_index() () のみにすること |
Warning
両方のキーカラムにキーが
nullである行が含まれている場合、これらの行は互いに一致します。これは通常のSQLの結合動作とは違う挙動になります。
参照ページ一覧
このブログを作成するにあたり、以下のページを参考にしています。併せてご覧ください。
1) データセットの結合 pd.concat 縦向き、横向き結合
2) 複数の行を連結して重複行を削除する
3) Merge Join Concat Dataframes