
データ分析の定番であるピボットテーブルでテータをグループ化して解析します。 データセットの数値データとカテゴリカル・データを組み合わせて解析します。
チートシート
| やりたいこと | コーディング |
|---|---|
| ピボットテーブルを作成する 計算列の値を平均する |
pd.pivot_table(df, values='計算列', index=['列1', '列2'], columns=['比較列1', '比較列2'], margins=True, aggfunc=np.mean) |
| 要素名 | 説明 |
|---|---|
| 計算列 | ピボットテーブルで計算したいデータの列 |
| 列1 | ピボットテーブルの親インデックス1 |
| 列2 | ピボットテーブルの子インデックス2 |
| 比較列1 | 集約列(親) |
| 比較列2 | 集約列(子) |
参照: pandas.DataFrame.pivot_table
Kaggle データで作成する
今回は、いつものデータフレームではなく、Kaggle よりTipデータ をダウンロードしてピボットテーブルを作成しました。 欠損値のチェックやデータセットの理解のための一連の作業は実施済です。 Kaggle で tips, restaurant と検索すれば出てくると思います・
サンプルデータセットについてにデータセットの概要があります。参考にしてください。
今回使うデータのポイント
- df.shape => 244 x 7
- 第二列のラベル名
tipsに客が置いたチップの金額 $ - 第三列以降に 「性別」、「喫煙・禁煙」、「木・金・土・日」、「ディナー・ランチ」
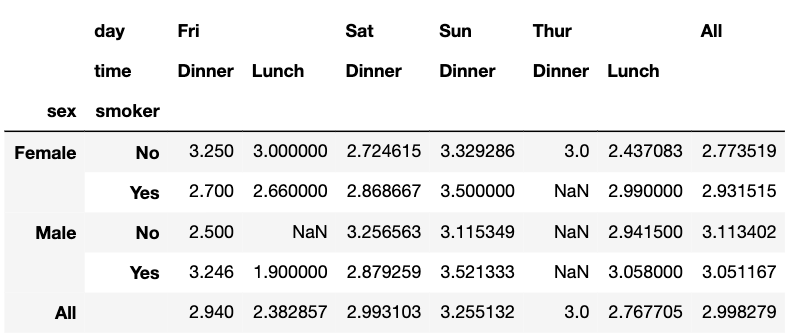
ピボットテーブルの構成
ピボットテーブルはインデックス行と比較列で集約(計算)した内容がテーブルの要素になります
- 性別と喫煙・禁煙の4つの組み合わせをインデックスとして
- チップの金額の平均を「曜日」と「ディナー・ランチ」ごとに集約します
- 最終列、最終行にそれぞれの行、列を計算します
- 集約する計算方法は平均値になります
1
2
# ピボットテーブルを作成する
pd.pivot_table(df, values='tip', index=['sex', 'smoker'], columns=['day', 'time'], margins=True, aggfunc=np.mean)
結果は以下のとおりですが、ビフォア、アフターで比較できるように、データフレームの最初5行も合わせて紹介します。今回は、np.meanで平均を計算してしますが、総和をとりたい場合はnp.sumになります。
オリジナルのデータセット
ピボットテーブル
ひとこと
EXCELではおなじみのピボットテーブルですが、データ集約では欠かせません。 集約しただけで、思わぬ発見やこれだけでデータセットの理解が進んで、解析の方向性にも大きく影響する場合があります。
groupbyと同様に理解したいですね。