
カテゴリカル変数を回帰分析等の説明変数として利用するためには、ダミー変数にする必要があります。
Pandas ではdummy = pd.get_dummies(dummy, prefix='td')でダミー変数化されたデータフレーム(dummy)を生成きます。
チートシート
| やりたいこと | コーディング |
|---|---|
| ダミー変数化したい列をシリーズデータ(dummy)として取り出す | dummy = df['ダミー変数したい列'] |
| シリーズデータ(dummy)をダミー変数のデータフレームにする | dummy = pd.get_dummies(dummy, prefix='td') |
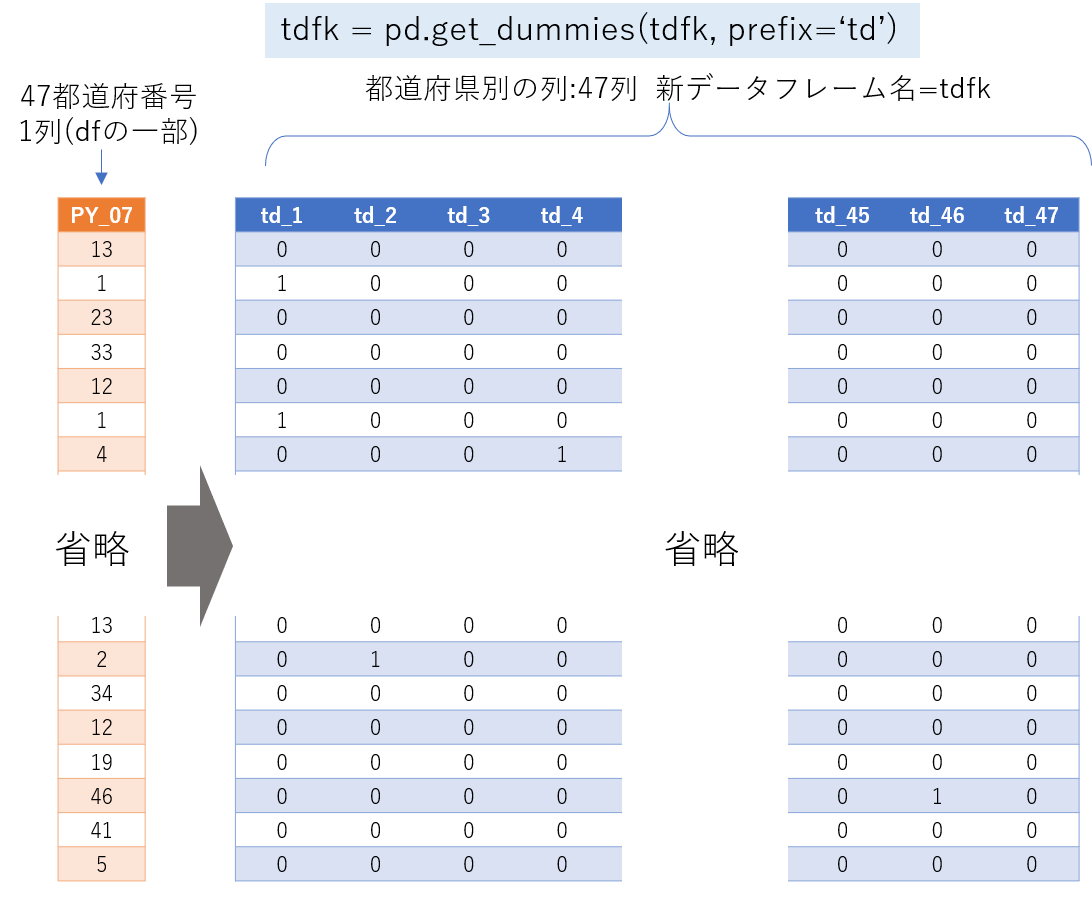
概念図
ダミー変数化の概念図は以下のとおりです。
ちなみに、作成する新データフレームtdfkは図中のコマンドを打つ前にSeries(配列)にして取り出す必要があります。その名前もtdfkとしています。
ポイント
- df内のカテゴリカル変数の列(タテ)を横に展開する
- 都道府県番号のように47種類ある場合は、47列生成される
- データフレームの行数(Length)は不変
pd.cancatで結合する- 変更元の列は不要なので削除することを忘れないようにする
one hop encoding の実際
本サイトでおなじみのオリジナルデータdf の都道府県番号が入っているPY_07をダミー変数化します。
1
2
3
4
5
6
7
# Series データとして取り出した後、ダミー変数化したデータフレムにする
tdfk = df['PY_07'] # series
tdfk = pd.get_dummies(tdfk, prefix='td')
# 元となるdfと新しく作成されたtdfk のサイズを見ます
print('df', df.shape)
print('tdfk', tdfk.shape)
結果は以下のとおりです。
(7485, 11)
(7485, 47)2つのデータフレームとも同じ行数です。次に、ダミー変数のデータフレームのtdfkをdf に連結します。 今回の連結には pd,concat メソッドでdf にtdfk を追加する感じで連結します。 また、ダミー変数化されたオリジナルの「都道府県番号が入った’PY_07’」は必要ありません。データフレームからドロップしてます。
1
2
3
4
5
# dfの前後のサイズをプリントしておきます
print('before', df.shape)
df = pd.concat([df, tdfk], axis = 1)
df = df.drop(columns=['PY_07'])
print('after', df.shape)
before (7485, 11)
after (7485, 57)dfの列名について確認します。
1
2
# 列名を出力します
df.columns
Index(['PY_02', 'PY_03', 'PY_05', 'PY_06', 'PY_09', 'PY_11', 'PY_12', 'PY_13',
'PY_14', 'PY_20', 'td_1', 'td_2', 'td_3', 'td_4', 'td_5', 'td_6',
'td_7', 'td_8', 'td_9', 'td_10', 'td_11', 'td_12', 'td_13', 'td_14',
'td_15', 'td_16', 'td_17', 'td_18', 'td_19', 'td_20', 'td_21', 'td_22',
'td_23', 'td_24', 'td_25', 'td_26', 'td_27', 'td_28', 'td_29', 'td_30',
'td_31', 'td_32', 'td_33', 'td_34', 'td_35', 'td_36', 'td_37', 'td_38',
'td_39', 'td_40', 'td_41', 'td_42', 'td_43', 'td_44', 'td_45', 'td_46',
'td_47'],
dtype='object')ひとこと
カテゴリカル・データをデータ解析の説明変数としてする場合には、ダミー変数化する必要があります。one hop encoding はカテゴリカル・データのダミー変数にするための手間を格段と減らしてくれます。 是非、使い慣れてください。