
生年月日(MM/DD/YY)から年齢を計算をします。文字列MM/DD/YYで年が二桁しかありません。
Kaggleでみつけた2016年リオデジャネイロオリンピックの選手リストを使って、Pandas で計算します。
サンプルデータセットについてにデータセットの概要があります。参考にしてください。
チートシート
| やりたいこと | Coding |
|---|---|
| 文字列の生年月日が格納されている列名”dob”をDatetimeオブジェクトにして、列名”DoB”として格納する | df[“DoB”] = pd.to_datetime(df[“dob”], format=”%m/%d/%y”) |
Warning
1/1/68 の68より小さい数字(xx <68)は、20xx と変換されます
従って、12/22/57 の生年月日は12/22/2057 となり、正しい結果は得られません。
MM/DD/YYYY のフォーマットで生年月日をハンドリングする必要があります。
strptimeについての記事 を参考にしてください!
Kaggle データで作成する
リオデータ を使って、生年月日を計算しました。 生年月日がMM/DD/YYと年が二桁であること。 データに欠損値があるので、必ず、その行を落とすなどして下準備が必要です。 Kaggle で RIO, Olympic と検索すると出てくると思います・
今回使うデータのポイント
- df.shape => 11538 x 11
- dob とある列が生年月日です
- 2016/07/01 時点の年齢としました
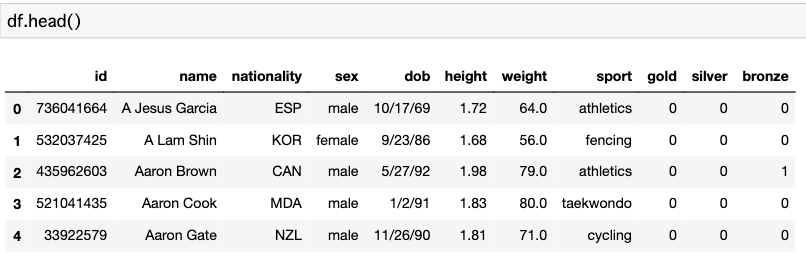
サンプルコーディング
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 下準備として文字列からオブジェクトにしておく
df["DoB"] = pd.to_datetime(df["dob"], format="%m/%d/%y")
# 年齢を計算する
def getAge(DoB):
today = int(pd.to_datetime('2016-07-01').strftime('%Y%m%d'))
DoB = int(DoB.strftime('%Y%m%d'))
return int((today - DoB) / 10000)
df['age'] = df['DoB'].apply(lambda x: getAge(x))
df.head()
# もしくは以下でも同じこと
now = pd.to_datetime('2016/07/01')
df['age']=(now.year - df['DoB'].dt.year) - ((now.month - df['DoB'].dt.month) < 0)
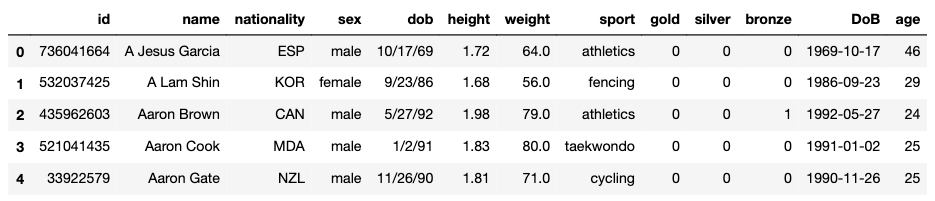
結果は以下のとおりです YYYY-MM-DD の形式のDoB 列を作成しその列に対してlambda関数で生年月日を計算しました。
計算結果のデータフレーム
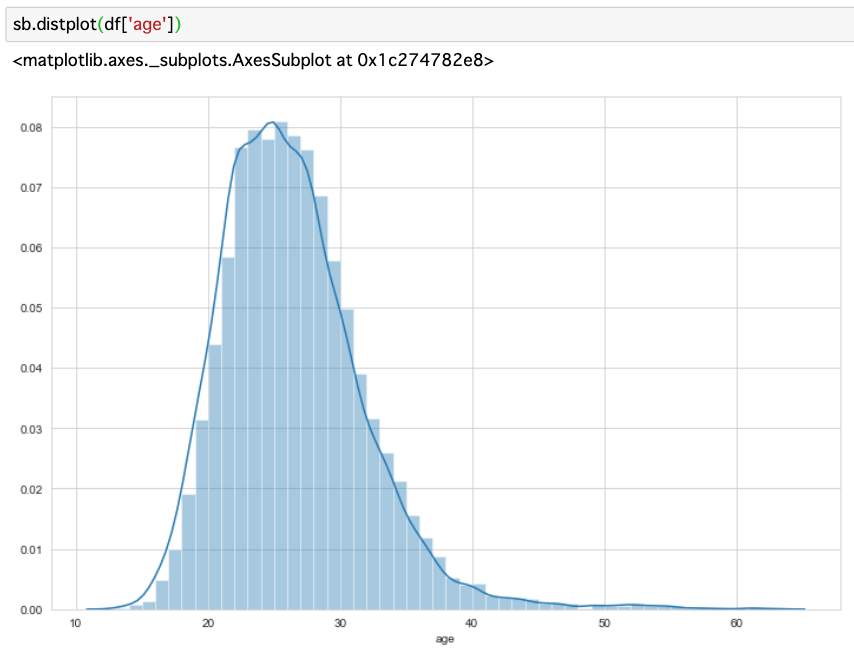
おまけ
密度関数のグラフ化もして分布の状況をみてみました。
ひとこと
df["DoB"] = pd.to_datetime(df["dob"], format="%m/%d/%y")はよく使われるコードですが
MM/DD/YYは母集団がある年齢層に偏っている場合に限り、注意して使う必要があります。