
データフレームの概要理解する “df_overview” スクリプトを紹介します。
🧩 データを俯瞰する作業は分析の最初の重要なステップ
データ分析を始めたばかりのとき、最もつまずきやすいのが 「データの全体像がつかめない」 という問題です。 列が多かったり、欠損があったり、文字列と数値が混ざっていたりすると、どこから手をつければよいのか迷ってしまいます。
そこで役立つのが、このページで紹介する df_overview スクリプトです。 列名・データ型・ユニーク数・欠損数などを一覧で確認できるため、データセットの特徴を短時間で把握し、次に行うべき前処理や分析の方向性を決める助けになります。
初心者にとって、こうした 「データを俯瞰する作業」は、分析の最初の重要なステップです。
🧩 スクリプトの内容
1
2
3
4
5
6
7
8
9
10
# 必要なモジュールをインポート
import numpy as np
import pandas as pd
# DataFrame 要約 列番号、列名、ユニーク変数数、データタイプ、NaN の個数
pd.options.display.max_rows = 220
## Check for unique values of categorical variables
df_overview = pd.DataFrame([[i, len(df[i].unique()), df[i].dtypes, df[i].isnull().sum()] for i in df.columns],
columns=['Feature', 'Unique Values', 'dtypes', 'NaN'])
df_overview
🧩 結果
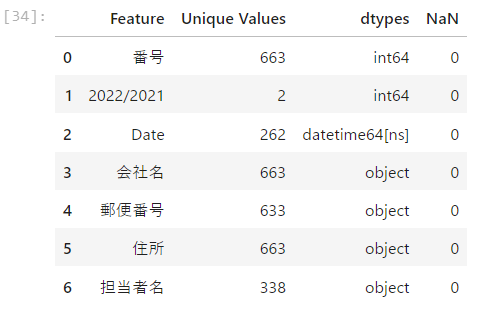
🧩「ユニーク数を見ると何がわかるのか」
ユニーク数(その列に含まれる異なる値の数)を見ることで、列の性質がつかめます。
例えば、ユニーク数が少なければカテゴリ変数の可能性が高く、逆に非常に多ければIDのような識別子かもしれません。
この情報は、どの列を分析に使えるか、どの列を前処理すべきかを判断する助けになります。
🧩「欠損値が多い列はどう扱うのか」
欠損値(NaN)が多い列は、分析の精度に影響するため注意が必要です。 欠損が多い列は、
(1) 削除する
(2) 平均値・中央値・最頻値で補完する
(3) モデルを使って補完する
(4) そもそも使わない列として除外する
などの判断が必要になります。まずは 「どの列にどれくらい欠損があるのか」 を把握することが、前処理の第一歩です。
🧩「データ型を確認する理由」
データ型(int, float, object など)を確認することで、その列がどのように扱われるべきかがわかります。 例えば、数字に見えるのに object 型になっている場合、文字列として扱われてしまい、計算や集計が正しくできません。 データ型の確認は、後の分析でエラーを防ぐための重要なチェックポイントです。
🧩「このスクリプトを使うと、どんな分析準備が楽になるのか」
df_overview を使うと、列名・ユニーク数・データ型・欠損数を一覧で確認できるため、次のような作業がスムーズになります。
(1) どの列を前処理すべきか判断しやすくなる
(2) カテゴリ変数・数値変数の分類がすぐにできる
(3) 欠損値の扱い方針を立てやすくなる
(4) 不要な列(ID列など)を早い段階で除外できる
つまり、データセットの全体像を短時間でつかみ、分析の準備を効率化できるのが最大のメリットです。
データフレームのインデックス番号、インデックス名を指定してその行を削除する
おまけとして、インデックス名を指定してその行を削除するとてもよく使うコマンドを併記します。
1
2
3
4
5
# データフレームの2行目にもタイトルの残骸があり、その行は無効なの
# 行を指定して削除する
# index[0] はデータフレームとしては最初の行だが、無効なため削除する
df = df.drop(df.index[[0]])