
このブログではデータハンドリングの基本である、DataFrame, ndarray, list の形式変換について「DataFrame, ndarray, list の使い分けについて実用的に考える」という問いに対してブログにしました。
データ分析をするデータセットはそのほとんどは、n行 x m列の2次元のデータです。2次元のデータを扱うためのデータ形式には、Pandas のデータフレーム、Numpyのndarray、Python標準の list が一般的です。それぞれの形式をその用途に合わせて変換します。
このブログでは、2次元のデータに絞って、以下の図をデータ分析の観点から使い方に合わせて変換できることを目標にしています。
DataFrame <-> ndarray <-> list 間のコンバージョン
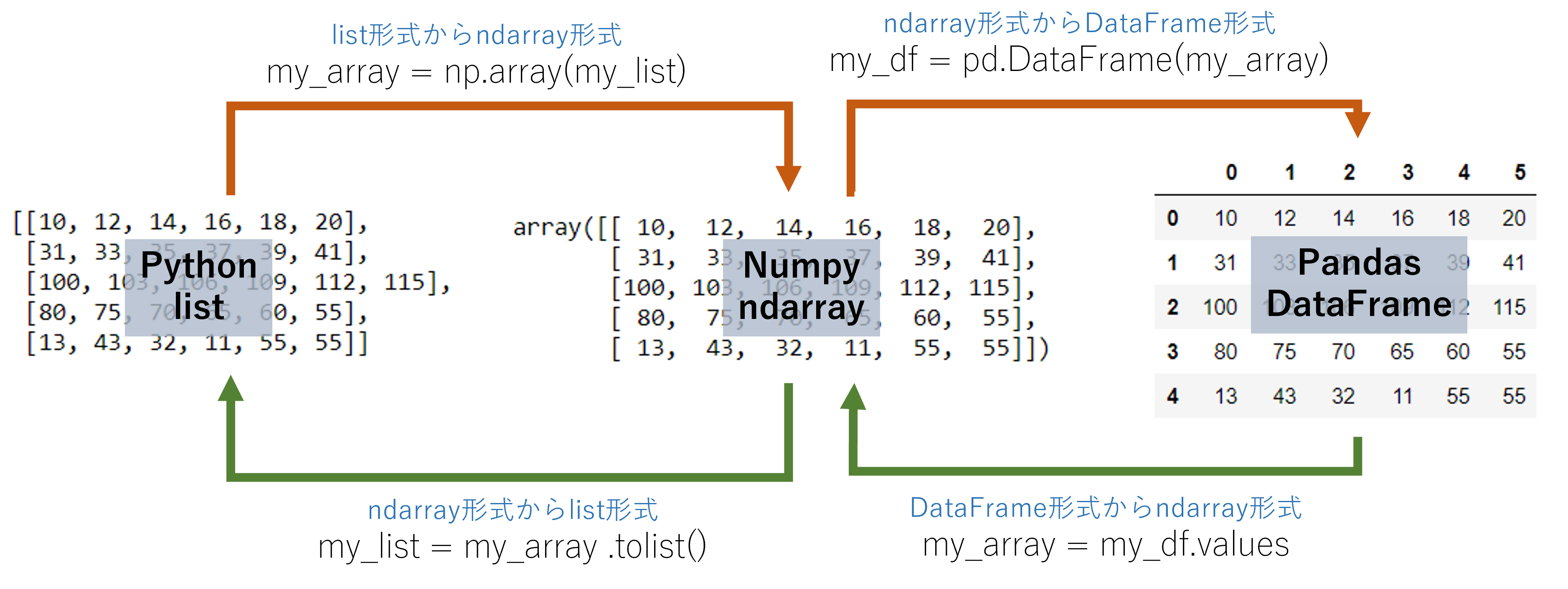
Pandas DataFrame がデータセットを用意するツール
Pandasは、Pythonでのデータ分析ライブラリとして最も活⽤されているライブラリです。Pandas はNumpyを基盤に、シリーズ(Series、1次元データ)とデータフレーム(DataFrame、二次元データ)という二つのデータ型を提供します。 データフレームは使いやすく、豊富な機能(メソッド)でデータ分析のための無くてはならないライブラリです。
- DataFrameはインデックス(index)やカラム(column)名を指定して、Excelのシートのようにデータセットを用意するために利用します
数値計算に特化したNumpy ndarray
Numpyを利⽤すると、Python標準のリスト型に⽐べて、多次元配列のデータを効率よく扱うことができます。また、Numpyは標準偏差や分散といった統計量を出⼒してくれる関数が⽤意されており、科学技術計算の基盤となっており、その延長線上で機械学習、ディープラーニングでも使われています。
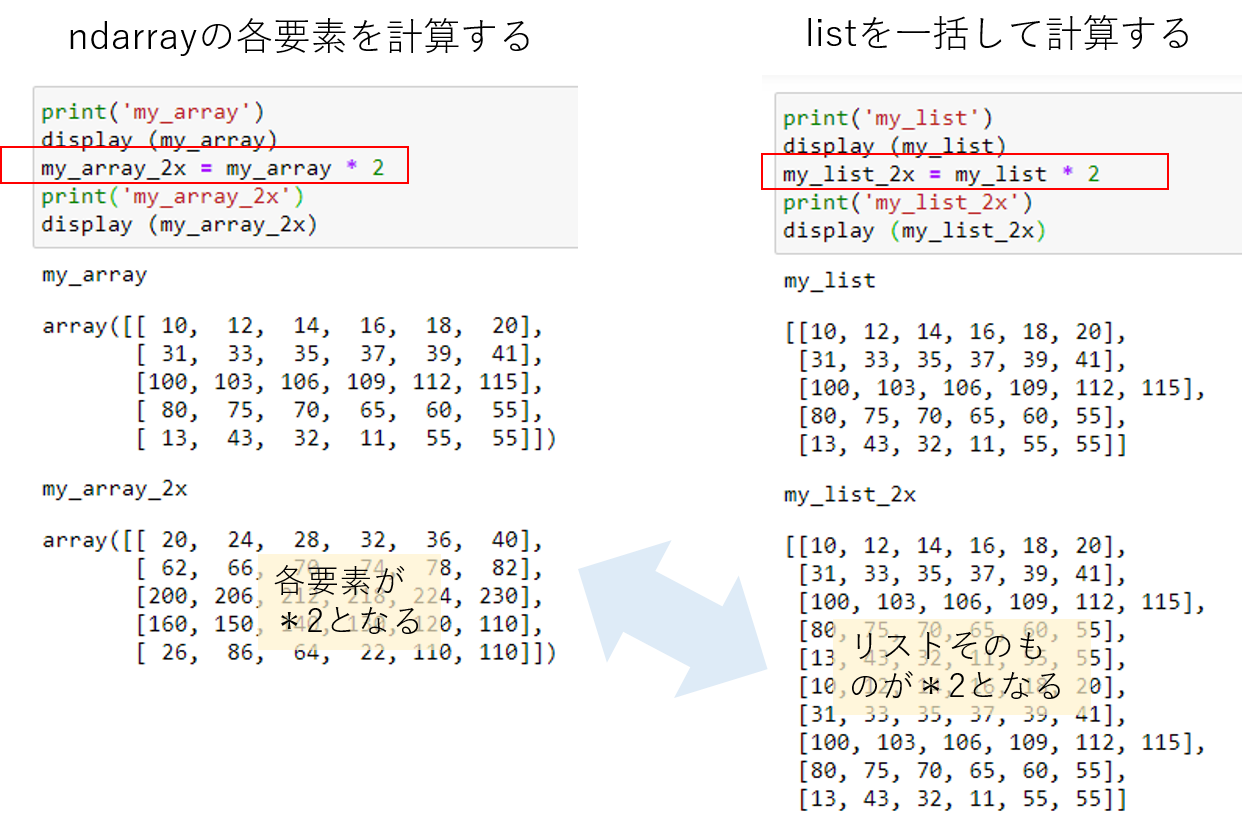
Numpyには、ndarrayと呼ばれるデータ型が⽤意されています。 ndarrayは⼀⾒すると、Python標準のリスト型(list)と似ていますが、ベクトル計算のように、内部の要素それぞれを⼀括して計算します。
ndarray と list の計算の違い
- 機械学習での学習用と検証用に分割したデータセットなど分析モデルの入出力形式です
Pandas, Numpyとも「統計量」を算出するメソッドは多数提供されています。Pandas の方が使いやすく、見やすいという意見も多いです。
Python標準の配列データの形式がlist
⼀つの変数に複数のデータを⼊れて扱う、配列データとして使うのが リスト型(list)です。したがって、Pythonプログラムの入出力の標準データ形式がlist ということになります。
- インデックス番号(添字と呼んだりします)で要素を指定することができる、Pyhtonプログラムの入出力データの標準的な配列形式です
まとめ
| DataFrame | ndarray | list | |
|---|---|---|---|
| 利用するライブラリ | Pandas | Numpy | Python標準 |
| ラベルインデックス (列、行に任意の名前を付けること) |
可(列名、行名を指定してにデータの操作が可能) | 不可(0から始まるインデックス番号で操作する) | 不可(0から始まるインデックス番号で操作する) |
| 特徴 | 使いやすい、メソッドが豊富 | 計算に特化した配列形式 | tuple, dictionaryと並ぶ配列形式の一つ |
| 目的 | 欠損値処理、標準化等の分析データの整形 | 機械学習、ディープラーニングの目的、説明変数等 | Pythonプログラムのデータの入出力等 |