
法人名、部署などフォームに自由入力された表記ゆれのあるデータを集計・分析のための名寄せ作業の一環である「全角を半角に統一する」のように決められたフォーマットに変換する方法についてBlogにまとめました。フォーム入力データの統一作業の参考になれば幸いです。
表記ゆれ
表記ゆれとは、同じ単語を書き表す際に、複数の標記が存在することです。表記ゆれにはパターンがあり、英語・日本語の表記ゆれ(「CB」と「シービー」)、カタカナの表記ゆれ(例:「ユーザ」と「ユーザー」)、数字の表記ゆれ(例:「3」と「三」)、送り仮名の表記ゆれ(例:「申し込む」と「申込む」)、全角・半角(例:「123」と「123])のゆれが代表的なパターンです。
今回取り上げる「法人名」「企業名」、「部署名」はフォーム入力者に関する属性データとして利用されることがよくあるデータの一つです。これらは選択式での入力が難しく、自由記述になることの多いのが特徴といえます。 自由記述のため集計・分析にあたり会社名等で同じ属性グループにまとめようとしても、その入力内容は以下のような表記ゆれが複数の入力者間で発生し、名寄せが難しいデータでもあります。
- 「株式会社 会社名」と「株式会社」と「会社名」の間に半角や全角スペースが入る
- 「ABC456株式会社」と「ABC456株式会社」英数字を半角または全角で入力される(カタカナも同様)
- 全角のカッコ(株)半角のカッコ(株) もしくは、(株) のように前後で全角と半角が入り乱れて入力される
但し、法人名等は固有名詞でかつ、フォーム入力者の属性情報としてとるのであれば、流石に自身が属する会社名の表記に英語・日本語の表記ゆれや、カタカナの表記ゆれ、送り仮名の表記ゆれは滅多にありません。
このBlogでは上記の3パターンについてクリーニング手法の実際をご紹介したいと思います。
サンプルデータフレームの紹介
以下のようなデータフレームを使ってクリーニングを行います。
1
2
3
4
5
6
7
8
9
10
11
12
import numpy as np
import pandas as pd
name = ['株式会社 元気123GO', '(株)ohta', 'KATO工業株式会社', 'AICE 商店', '株式会社 山田産業', '日本アイス・クリーム', '青木旅行 co.ltd']
num =[134,45,1045,59,602,666,213]
tdfk = [13, 19, 22, 46, 7, 33, 13]
#Make DataFrame
df = pd.DataFrame({"法人名": name,
"社員数": num,
"都道府県番号": tdfk})
df.head(10)
半角及び全角スペースを取り除く
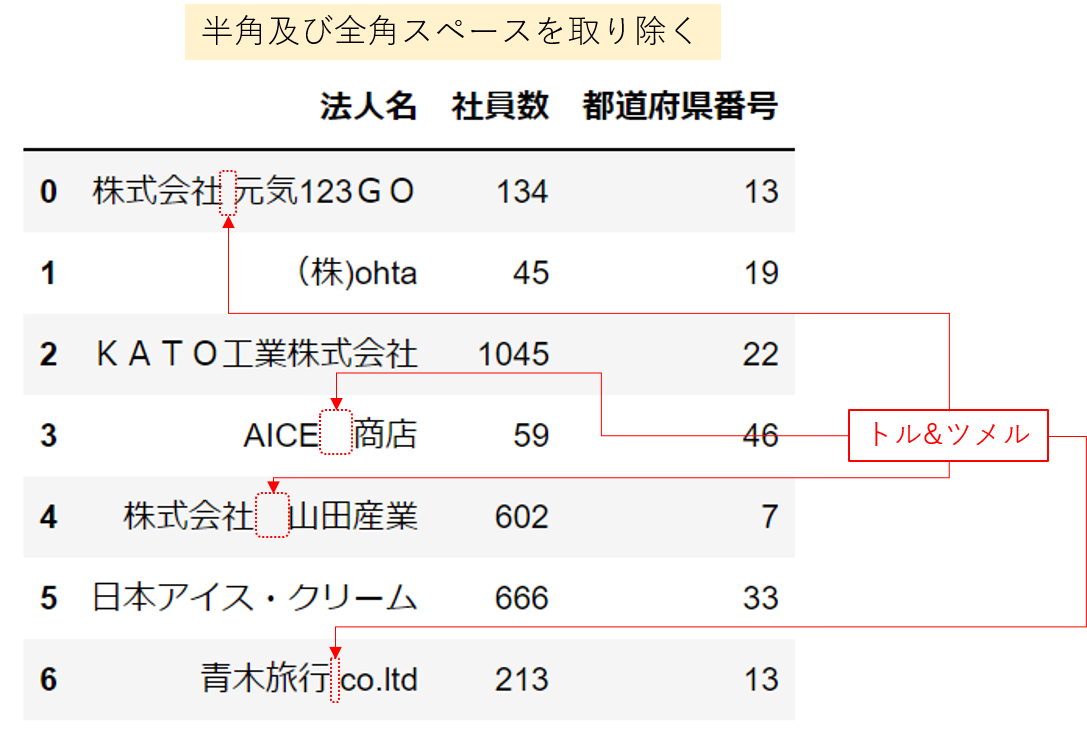
PandasとNumpyを使ってまず全角を取り除きます。 全角は\u3000です。
1
2
3
4
5
6
7
8
9
10
values = df['法人名'].values
values = values.tolist()
list = []
for item in values:
item_mod = item.replace("\u3000", "")
list.append(item_mod)
array = np.array(list)
df['法人名']=pd.DataFrame(array)
同様に、半角を取り除きます。
1
2
3
4
5
6
7
8
9
10
values = df['法人名'].values
values = values.tolist()
list = []
for item in values:
item_mod = item.replace(" ", "")
list.append(item_mod)
array = np.array(list)
df['法人名']=pd.DataFrame(array)
英数字、記号の全角を半角に統一 カタカナは全角のまま
カタカナは、ひらがなと同様に全角のままとして、英数字と記号は半角に統一します。
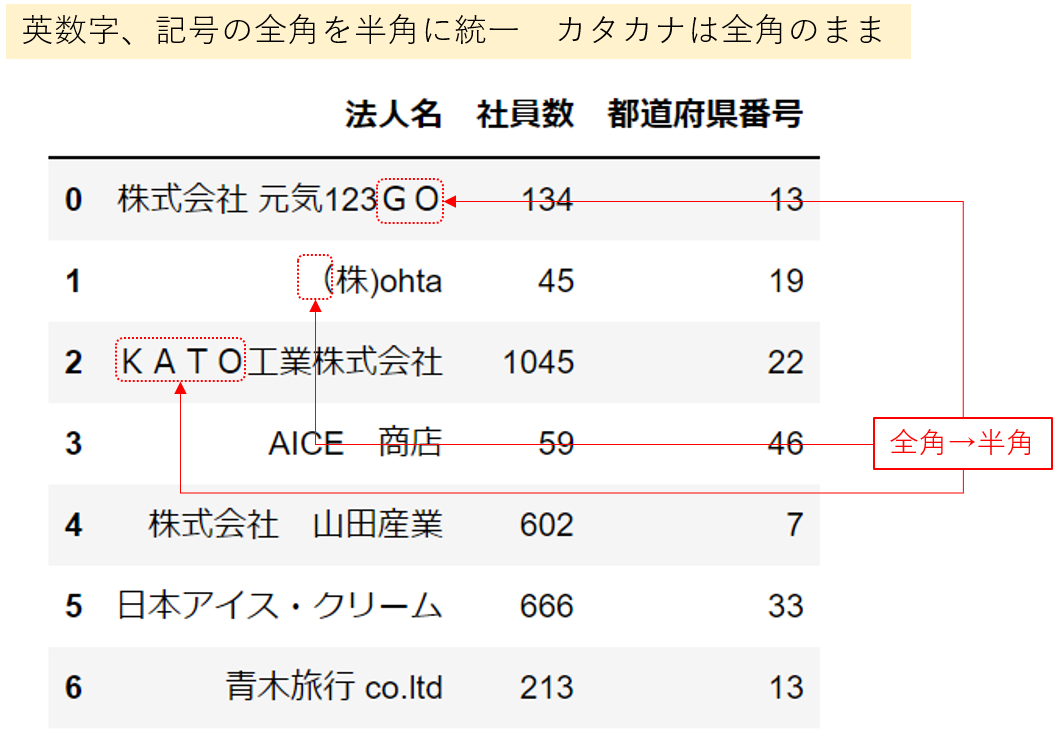
ここでは、mojimoji というモジュールを利用します。 このモジュールが入っていない場合は
pip install mojimoji でモジュールをインストールする必要があります。
カタカナを除く、英数字・記号を「全角」から「半角」にするので、
df['法人名'].apply(mojimoji.zen_to_han, kana=False) とカナを除外kana=False としています。
1
2
3
import mojimoji
df['法人名'] = df['法人名'].apply(mojimoji.zen_to_han, kana=False)
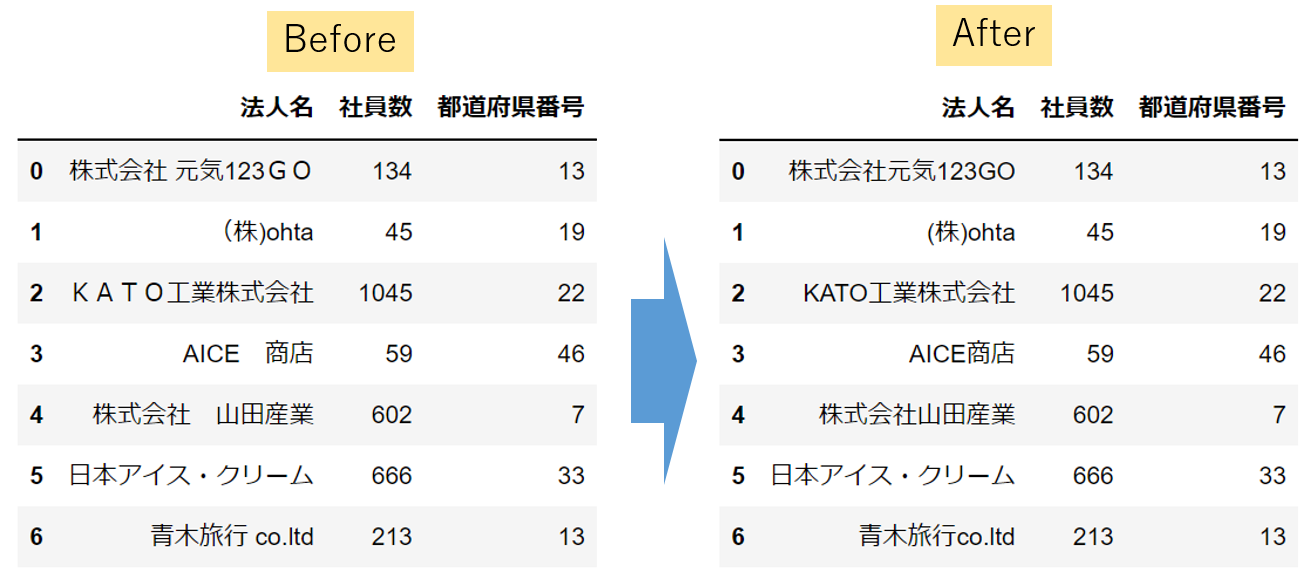
Before After
参照ページ一覧
このブログと一緒にこのサイト内の以下のページも併せてご覧ください。
1) データクリーニングの備忘録
2) カラムデータの特定語句の有無を判定しカテゴリ化する
3) DataFrame, ndarray, listの使い分けについて実用的に考える