
ビジュアライゼーションツールであるSeabornを使って3グループのそれぞれ2値の比較を棒グラフとデータラベルで可視化を行う方法をまとめました。
ターゲット画像
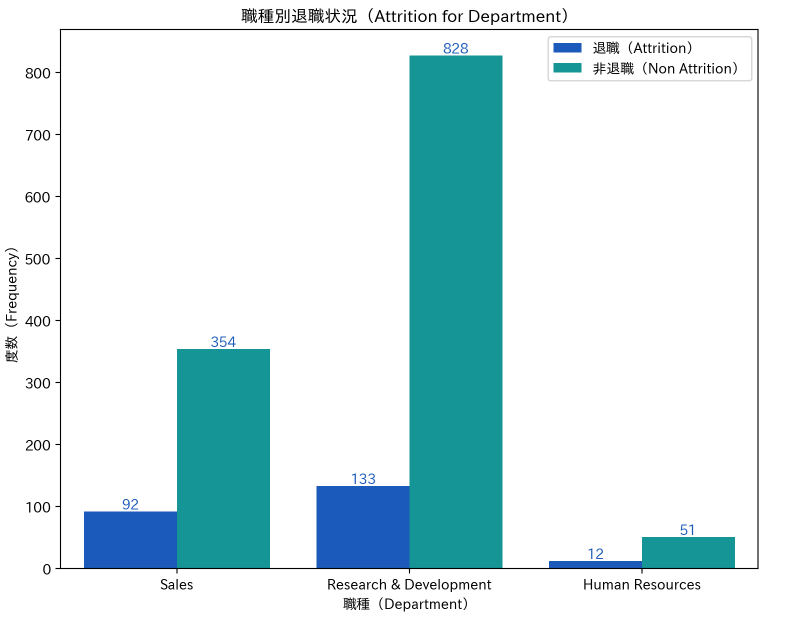
このページで作成する画像は、以下の図となります。
サンプルデータセットの紹介
データセットを利用しながら、説明をします。 Sample Datasetで紹介した、HRデータ(データセット3)の一部のカラムを利用して具体的に説明したいと思います。
このデータセットは、Attrition に影響する従業員の属性について分析するためのものです。 「Attrition(アトリション)」は、組織や企業において従業員の離職や退職のことを指す言葉です。従業員の流出や離脱とも訳されます。 企業や組織は、Attritionの影響を最小限に抑えるために、離職率や離職原因の分析、従業員の定着策やキャリア開発プログラムの実施などの対策を取ることがあります。また、Attritionの率や傾向は、組織の人材計画や採用戦略にも影響を与える重要な指標となります。
Attrition 影響分析としてGender(性別)とDepartment(所属部門)で一見して差異があるかをどうかを可視化します。
データセットは以下のとおりです。
表示結果df.head()は、以下のようになります。

データセットの大きさは、1470 x 10 です。そのうち、
- Attrition が退職(Yes)と非退職(No)
- Gender は男性(Male)、女性(Female)の2値
- Department は、3部門 (
SalesResearch & DevelopmentHuman Resources)
groupby メソッドでクロス集計する
今回はgroupby メソッドをクロス集計を行います。groupbyを使うとピンポイントに簡単に集計を行うことができます。
1
df.groupby(['Department','Attrition'])['Department'].count()
結果は、以下のとおりです。

結果を見ていただければわかるとおり、DepartmentごとのAttritionをDepartmentをキーにして各々の数を集計します。
このままでも集計結果は理解できますが、それを棒グラフにして各Departmentごとの差異を数字及び棒の大きさで視覚的に示します。
Seaborn のcountplotを使って可視化する
ターゲット画像で示したとおり、各職種ごとにAttritionとNon-Attritionを対比した棒グラフを作成するためのスクリプトは以下のとおりです。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
import numpy as np
import pandas as pd
import seaborn as sns
# matplotlibのグラフをRetinaの高解像度で表示する
%config InlineBackend.figure_formats = {'png', 'retina'}
# Jupyter Notebookの中で作図した画像を表示させる
%matplotlib inline
# matplotlib をインポートする
import matplotlib.pyplot as plt
# 日本語タイトルのため、japanizeをインポートする
import japanize_matplotlib
plt.rcParams['font.family'] = 'IPAexGothic'
#show Attrition Frequency for Department
plt.figure(figsize=(9,7))
ax = sns.countplot(x = df['Department'], data=df, hue='Attrition',palette="winter")
plt.title('職種別退職状況(Attrition for Department)')
plt.xlabel('職種(Department)')
plt.legend(["退職(Attrition)", "非退職(Non Attrition)"])
plt.ylabel('度数(Frequency)')
for i in range(2):
ax.bar_label(ax.containers[i], fontsize=10, color = '#1b5aba');
plt.show()
結果は以下のとおりです。
seaborn.countplot の詳細
可視化の要となるax = sns.countplot( data=df, x = df['Department'], hue='Attrition',palette="winter")について説明したいと思います。詳しい説明は、
seaborn countplotを参考にしてください。
- data
- データフレームを指定します。対象データセットです
- x
- x軸とするカラムを指定します。今回は`Department`
- hue
- 色合いの英語であるhue から各色の意味=右上の凡例の表記をさせます。
- palette="winter"
- 棒グラフの色をパレットで指定しています。この例では"winter"パレットを指定しました。
データラベルを付ける
データラベルは、以下のCoding で実現しています。bar_label()を利用すると簡単に実現できます。
ちなみに、range(2)の2 は
比較対象で hueで
凡例としている Attrition/Non Attrition の
2値の2が入ります。
1
2
for i in range(2):
ax.bar_label(ax.containers[i], fontsize=10, color = '#1b5aba');
参照ページ一覧
このブログを作成するにあたり、以下のページを参考にしています。併せてご覧ください。
1) サンプルデータセットの説明
2) df.value_counts() の結果をパワポ用にビジュアル化する
3) クロス集計表とヒートマップでデータセットを理解する