
Pythonを使って複数のexcelファイルの同じ場所のセルの値を一つのシートにまとめる入力作業機械化方法を解説します。
自動化の手段としてEXCEL マクロ(vba)で組むのも一つの方法ですが、Openpyxl のモジュールを使えば簡単に実現できる場合があります。複数のexcelファイルの内容を一つのシートにまとめる作業の時短について、Blogにまとめました。旧ページの紛らわしい記述を修正しています。
自動化のイメージ
自動化のイメージは下図になります。
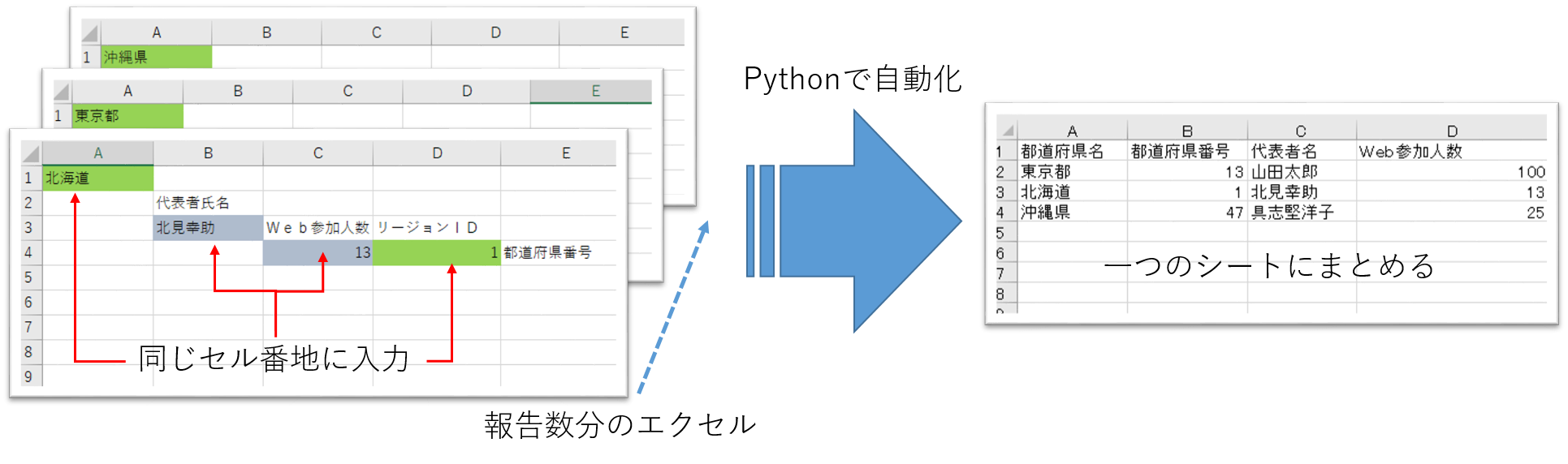
集計にあたり、以下のような一般的なEXCELを使った報告シートを想定してプログラムを組んでいます。
1) 報告数分のEXCELファイルにそれぞれシートが一つ存在します(複数のシートがある場合最初のシートが対象になります)
2) 入力シートのようにそれぞれのEXCELファイルのシート内の同じセルの位置に入力されています
3) ファイル名はそれぞれ異なり、一つのフォルダにまとめてあります
4) 集計するセルの場所(番地)は固定で予め決まっています
5) 集計するセルの場所以外に入力された内容は集計しません(できません)
Openpyxl
Openpyxl とはPythonでExcel ファイルを読み書き等の操作するためのモジュールです。一旦、EXCELファイルをPythonのプログラムで読み込んでしまえば、値の挿入から書式の変更までPythonプログラムやJupyter Notebook上でEXCEL操作が可能になります。
glob
複数のExcelファイルを読み込むために、glob を利用します。 以下のサンプルでは、Dドライブのjupyterというフォルダ配下にあるxlsxの拡張子があるExcelファイル: workbook(gb)を順次読み込ませ、読み込んだエクセルのbookの最初のシートworksheets[0]を ws2としています。
1
2
3
4
input_file_name= 'D:\jupyter\\*.xlsx'
for gb in glob.glob(input_file_name, recursive=True):
ws2 = xl.load_workbook(gb).worksheets[0]
リスト形式でシート内のデータを格納
globを使ってフォルダ内のExcelファイルを順次読み込んでのち、それをリスト形式で変数に格納するもう一つテクニックがあります。一行で実現できます。これも覚えておくと便利なコードテクニックです。
1
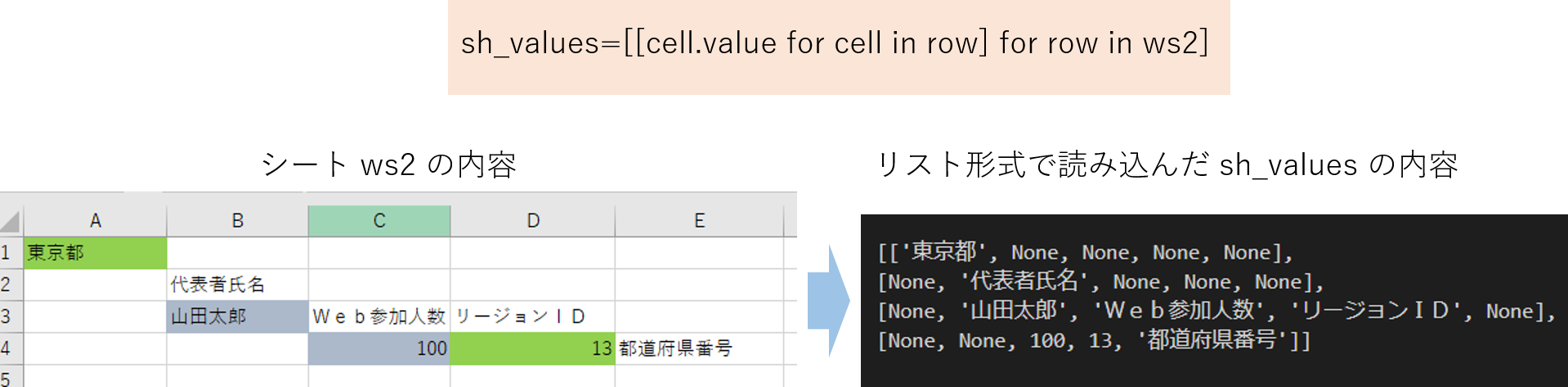
sh_values=[[cell.value for cell in row] for row in ws2]
読み込んだシート(この場合はws2ですね)の各行を変数 sh_values にリスト形式で格納してくれます。
[['東京都', None, None, None, None],
[None, '代表者氏名', None, None, None],
[None, '山田太郎', 'Web参加人数', 'リージョンID', None],
[None, None, 100, 13, '都道府県番号']]Excel シートデータとリスト配列の関係
Excel シートデータとリスト配列の対応関係を図示します
変数の定義
各変数の働きをまとめておきます。筆者も久しぶりに記事を参考にしてコーディングしようとしたところ、ハマりました。ページ修正にあたりまとめてました。
- ws
- output(書き込み)用のworksheet
- ws2
- globで順次読み込まれるworksheet
- sh_values
- ws2の全データをリスト形式で格納します
- wb.xlsx
- 書き込み用の excel ファイル、load するため事前にファイルを用意する必要がある
- saved.xlsx
- 結果が保存される excel ファイル
サンプルコード
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import openpyxl as xl
import glob
input_file_name= 'D:\\jupyter\\*.xlsx'
output_file_name = 'D:\\work\\wb.xlsx'
saved_file_name = 'D:\\result\\saved.xlsx'
book = xl.load_workbook(output_file_name)
ws = book.active
line_num = 2
for gb in glob.glob(input_file_name, recursive=True):
ws2 = xl.load_workbook(gb).worksheets[0]
sh_values=[[cell.value for cell in row] for row in ws2]
ws.cell(row=line_num,column=1).value = sh_values[0][0]
ws.cell(row=line_num,column=2).value = sh_values[3][3]
ws.cell(row=line_num,column=3).value = sh_values[2][1]
ws.cell(row=line_num,column=4).value = sh_values[3][2]
line_num+=1
book.save(saved_file_name)
サンプルコードのLine by Line の説明
2. 同上
3. 取りまとめるフォルダと配下のExcelファイル*.xlsを指定する。コードでは以降、D:\\jupyter\とする。
4. 書き込みファイル名を wb.xlsx と定義し、結果を書き込む
5. saved.xlsxという別名で保存する。
6. 書き込み用wb.xlsx(output_file_name) を読み込み、bookというオブジェクトに格納
7. アクティブシートを ws という名前で定義し、このシートに値を代入する
8. 最初の書き込み位置を2行目line_num = 2にセットする
9. 定数 'input_file_name'で指定したフォルダ配下の excelファイルがひとつづつ読み込まれる
10. 読み込まれるExcel bookの最初シートworksheets[0]をws2と定義する
11. ws2にある値を各行ごとのリスト形式です読み込む
12. wsの line_num行1列目column=1にsh_valuesの(0,0)=>1行目の1列目の値(都道府県名)を代入する
13. wsの line_num行2列目column=2にsh_valuesの(3,3)=>4行目の4列目の値(代表者名)を代入する
14. wsの line_num行3列目column=3にsh_valuesの(2,1)=>3行目の2列目の値(Web参加人数)を代入する
15. wsの line_num行4列目column=3にsh_valuesの(3,2)=>4行目の3列目の値(都道府県番号)を代入する
16. line_numを +1 する
17. bookをセーブする。ファイル名はsaved_file_nameで定義している
ひとこと
メールでEXCELファイルを送信し、決められたフォームに必要事項を入力してもらって記入済のEXCELファイルを取りまとめるという作業はメールとEXCELがオフィスツールとして定着した30数年前から今日まで根強く蔓延ったルーチン作業の一つだと思います。
課内等の10数件であれば、一時間もあれば手作業でも完了しますが、全国47都道府県分であるとか、全国営業店、支店から等で100件以上の三桁のオーダーとなると手作業では半日以上かかることも少なくありません。
Pythonを駆使して時短に挑戦する価値があるルーチン作業だと思います。