
データセットの準備は、データセットの理解で始まり、クレンジングで終わると言えます。このブログではデータ分析の一丁目一番地である データセットの理解のためのスクリプト4選をご紹介いたします。
サンプルデータセットの紹介
データセットを利用しながら、説明をした方が分かりやすいと思いますので、今回は Sample Datasetで紹介した、HRデータ(データセット3)の一部のカラムで 4選スクリプトを紹介いたします。
このデータセットは、Attrition に影響する従業員の属性について分析するためのものです。 「Attrition(アトリション)」は、組織や企業において従業員の離職や退職のことを指す言葉です。従業員の流出や離脱とも訳されます。 企業や組織は、Attritionの影響を最小限に抑えるために、離職率や離職原因の分析、従業員の定着策やキャリア開発プログラムの実施などの対策を取ることがあります。また、Attritionの率や傾向は、組織の人材計画や採用戦略にも影響を与える重要な指標となります。
今回は、Attrition 影響分析として提供されたデータセットがどんな内容なのかを理解するために利用したいスクリプトをご紹介いたします。
No.1 データフレームの各列の列名、ユニーク数、型、NaNの数の一覧表作成(Script)
データセットを読み込んで、何度もお世話になるスクリプトです。このスクリプトで各カラム(Featureとしています)の以下の特性を一覧表示させます。
- データのユニーク数(いわゆる、nunique)
- データの型(dtypes)
- NaN (null 総数)
df_overview というデータフレームで上記の内容を一覧表示させます。
1
2
3
4
df_overview = pd.DataFrame([[i, len(df[i].unique()), df[i].dtypes, df[i].isnull().sum()] for i in df.columns],
columns=['Feature', 'Unique Values', 'dtypes', 'NaN'])
df_overview
表示結果は、以下のようになります。 データフレームに整形されているのでとても見やすくなっていますね。
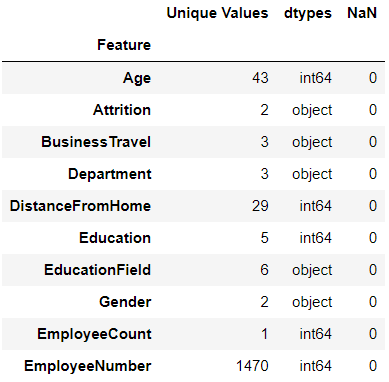
このスクリプトは、多変量解析をする説明変数(従属変数、Features)候補を検討する際にとても有用です。 今回のデータセットのサイズは、1470 x 10 ですが、EmployeeNumber というカラムは、1470種類あります。これは、社員番号のたぐいの変数のため 説明変数から外します。
また、その上のEmployeeCountですが、これは全て同じ値です。これも、説明変数としては不適となります(一種類では説明変数とはならないため)。これも 説明変数から外します。
No.2 ユニークな値の全部または一部を一覧表示する
各カラム毎のユニークな値の総数が分かりましたので、その中身について全部または一部を一覧表示し、特性を理解するのに役に立つスクリプトが以下になります。
1
2
for col in df.columns:
print(col, len(df[col].unique()), df[col].unique())
結果は以下のとおりです。

結果から以下のような考察が可能です。
- Age
- 年齢は、43種類でどうやら18から60歳まで存在しているようです。どんな分布かを次に知りたいところです。
- Attrition
- 退職した(Yes)またはとどまっているか(No)かの二種類です。このデータセットではこのカラムを目的変数として分析をしますので、True/False の0/1 への変換が必要となることが分かります。
- BusinessTravel(3種類),DistanceFromHome(3種類), EducationField(6種類)
- すべてカテゴリカルデータ(質的データ)ですので、分析を行うにはダミー変数(one hop encoding)化して、各データに対して0/1の値で横並びに変換する必要があります。
- DistanceFromHome, Education
- 順序変数と考えられます。順序変数は、データの値に順序があることを示しますが、値の間隔や比率には意味がないとされます。
- Gender
- 性別を'Female' 'Male'でデータ化されていますので、これを分析に使うであれば、0/1 に変換したいと思います。
No.3 度数分布図で可視化する
度数分布表で可視化してどんな分布かをクイックに理解するためのスクリプトです。 ここでは、seaborn ライブラリを使っています。
1
2
3
4
5
import seaborn as sns
col_name = 'Age'
sns.countplot(x=col_name, data=df, palette='hls')
ax = sns.countplot(x = col_name,
data = df)
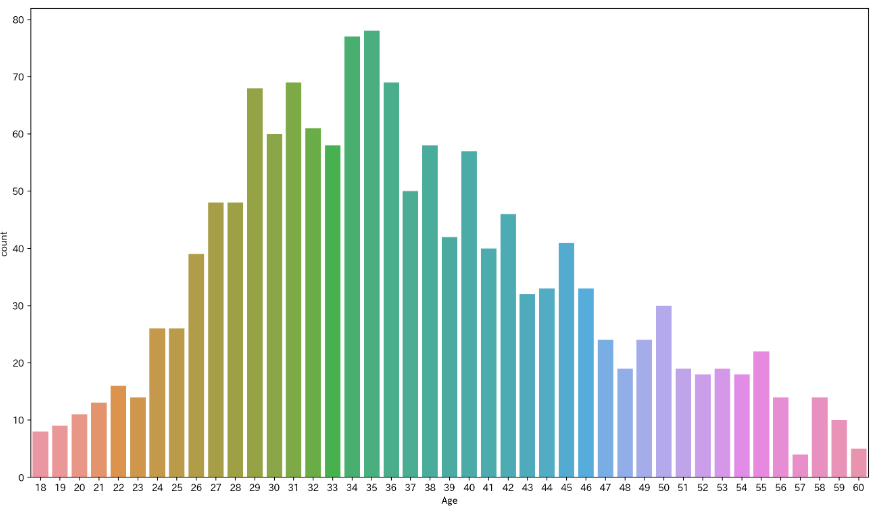
結果は、以下のとおりです。 可視化することで、一目瞭然ですね。 seaborn ライブラリを使うと、色合いが簡単に設定できるため、見栄えもよくそのままプレゼン資料に転用も可能です。
No.4 各度数と構成比% をデータフレーム形式で表示する
このスクリプトは、別のブログで紹介したものですが、Gender カラムように可視化せずとも、度数と割合で十分な場合も多々あります。このスクリプトを利用すればカラム名を指定するだけで、度数(今回は人数としています)と構成比を簡単に表示してくれます。
1
2
3
4
5
6
7
8
col_name = 'Gender'
tab = df[col_name].value_counts()
tab = pd.DataFrame(tab)
tab = tab.rename_axis(col_name)
tab['構成比']=(tab[col_name] / tab[col_name].sum())
tab.rename(columns={col_name: '人数'}, inplace = True)
format_dict = {'構成比': '{:.1%}'}
display(tab.style.format(format_dict))
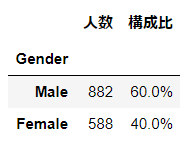
結果は以下のとおりです。
度数のパーセント表示はformat_dict = {'構成比': '{:.1%}'}で
小数点1位までにしています。
参照ページ一覧
このブログを作成するにあたり、以下のページを参考にしています。併せてご覧ください。
1) サンプルデータセットの説明
2) df.value_counts() の結果をパワポ用にビジュアル化する
3) クロス集計表とヒートマップでデータセットを理解する
4) データフレーム内の列間の値を比較する