
この記事では、Jupyter NotebookのPandasを使用してデータ分析を行う際に、
sqlite3で提供されるSQL文を使用してデータの読み込みと抽出操作をまとめました。
このブログがPythonプログラムでSQL操作を行う際に役立つことを願っています。
SQlite とは
SQLiteは、Cライブラリで、軽量なディスク上のデータベースを提供します。 サーバプロセスを別途用意する必要がなく、SQLクエリー言語(SQL文)を使用してデータベースにアクセスできます。 SQLiteを使用することで、アプリケーションのプロトタイプを迅速に作成し、そのコードを後でPostgreSQLやOracleなどの大規模データベースに移行できます。 そのため、SQLiteは、SQLデータベースを使うアプリ開発においては必須のツールとなっています。
DB Browser for SQLite とは
DB Browser for SQLiteは、 SQLiteデータベースを管理するためのソフトウェアです。 SQLiteデータベースの作成、閲覧、編集が可能で、データベースの最適化によってファイルサイズを小さくすることもできます。 また、USBドライブから起動できるポータブル版も提供されており、 SQLiteをより身近に利用できるようになっています。 多くの人がこのソフトウェアを利用した経験があるかもしれません。
sqlite3 モジュールとは
sqlite3モジュールは、 Python上でデータセットをSQLデータベースとして格納し、 SQL文を使用してアクセスするためのインターフェイスを提供します。 このモジュールを使用することで、PythonでSQLiteの操作を行うことができます。
サンプルデータセットとその読み込み方法について
サンプルデータセットで紹介した「データセット3: HR データ」を使います。他のデータセットでももちろん可能ですが、このデータセットに興味のある方は、Kaggle_HR_attritionで検索してデータセットをダウンロードしてください。
カレントディレクトリにダウンロードしたデータセットを配置して、Dataframeとして読み込みます。読み込むコードは以下のとおりです。
1
2
3
4
import codecs
with codecs.open("WA_Fn-UseC_-HR-Employee-Attrition.csv",
mode ="r", encoding ="utf-8", errors="ignore") as file:
df = pd.read_csv(file, delimiter =",", header=0)
今回は、データクリーニング前のRaw Data の読み込みを前提としているため、 UnicodeDecodeErrorで csv ファイルが読み込みエラーになるでもご紹介している方法でCSV形式のファイルを読み込みます。ポイントは以下のとおりです。
mode ="r"読み込みモードを指定します。encoding ="utf-8"インターネットからダウンロードした場合は、utf-8を指定します。Windows PC(Excel)で操作したデータを使う場合は、shift-jisを指定します。errors="ignore"を指定してデコードできない文字が含まれていた場合に無視(ignore)するを指定します。- CSVファイルをデータフレームとして読み込むにあたり
delimiter =","CSVファイルなのでカンマを区切り文字にします。header=0最初の行をヘッダーとして扱います。
sqlite DB を定義する
SQliteDBを作成します。DB名はHR_Employee_Attrition.dbとしています。以下のCode でDBを作成します。
ここでは、コメントにもあるとおりHR_Employee_Attrition.db`という名前のDBがなければ作成し、接続して使えるようにします。
すでに存在する場合は接続して使えるようにします。
1
2
3
4
5
6
7
8
#モジュールをインポートします
import sqlite3
#HR_Employee_Attrition.db という名前のDBをなければ作成して接続する
dbname = 'HR_Employee_Attrition.db'
conn = sqlite3.connect(dbname)
cur = conn.cursor()
SQlite DBにテーブルを定義し、データフレームの中身をテーブルに流し込む
DB名はHR_Employee_Attrition.dbでその情報はconnectionオブジェクト conn で引き継がれます。
DB内のテーブル名はHR_Employee_Attrition_tabと定義します。
1
2
3
# tableのnameを"HR_Employee_Attrition_tab"とし、読み込んだcsvファイルをsqlに書き込む
# index=False としてindex は書き込まないようにする
df.to_sql('HR_Employee_Attrition_tab', conn, if_exists='replace', index=False)
if_exists='replaceでテーブルが既に存在していた場合、上書きします。- データフレームが持つIndexはテーブルには書き込ませません。SQLite DB は独自にIndexを持ちますので、不要ですので、
index=Falseを指定します。
ls コマンドでファイルを確認すると、217,088 バイトの大きさでHR_Employee_Attrition.dbというDBが作成されています。
1
2
3
4
5
6
7
8
9
10
ドライブ D のボリューム ラベルは ボリューム です
ボリューム シリアル番号は C64A-8xx です
D:\jupyter\sqliteDB のディレクトリ
2023/03/0x 14:35 <DIR> .
2023/03/0x 14:35 <DIR> ..
2023/03/0x 14:35 217,088 HR_Employee_Attrition.db
1 個のファイル 217,088 バイト
2 個のディレクトリ 212,100,857,856 バイトの空き領域
SQLite DB にアクセスしてSQL文を実行する
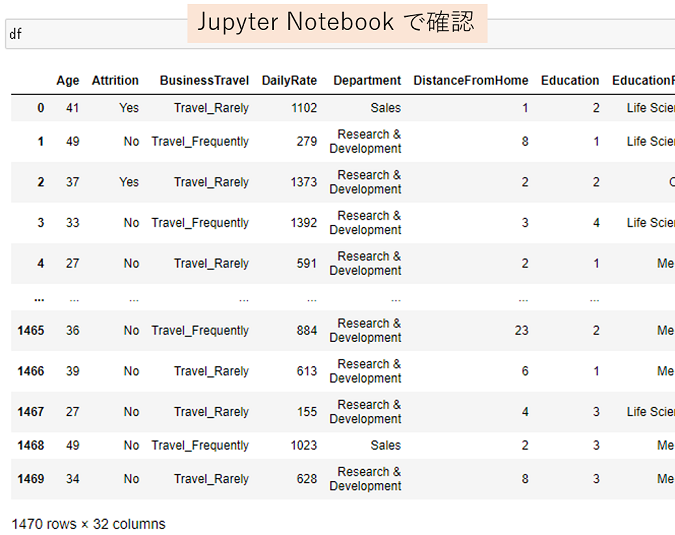
作成したSQlite DBにJupyter Notebook からアクセス(接続)し、SELECT文を使ってテーブルの中身を抽出します。 抽出したデータは、Pandas データフレームとして取り込みます。 以下のSELECT文では、テーブル全体すなわち、DBのデータ全部をデータフレームとして読み込むこととなります。
1
2
3
4
5
6
7
8
9
dbname = "HR_Employee_Attrition.db"
conn = sqlite3.connect(dbname)
cur = conn.cursor()
# dbをpandasで読み出す。
df = pd.read_sql('SELECT * FROM HR_Employee_Attrition_tab', conn)
cur.close()
conn.close()
Jupyter Notebook から内容を確認します。
Here Document でSELECT文の見通しの良さをアップする
SELECT文等でクエリを組み込みますが、Pythonでは、区切り文字として引用符を3つ続ける「"""」文字列リテラル(いわゆる、ベタ打ち文字列)を持つことができます。 改行できるため、抜き出すカラム名で改行させかつ、Query として独立させ、全体を見通しを良くさせます。
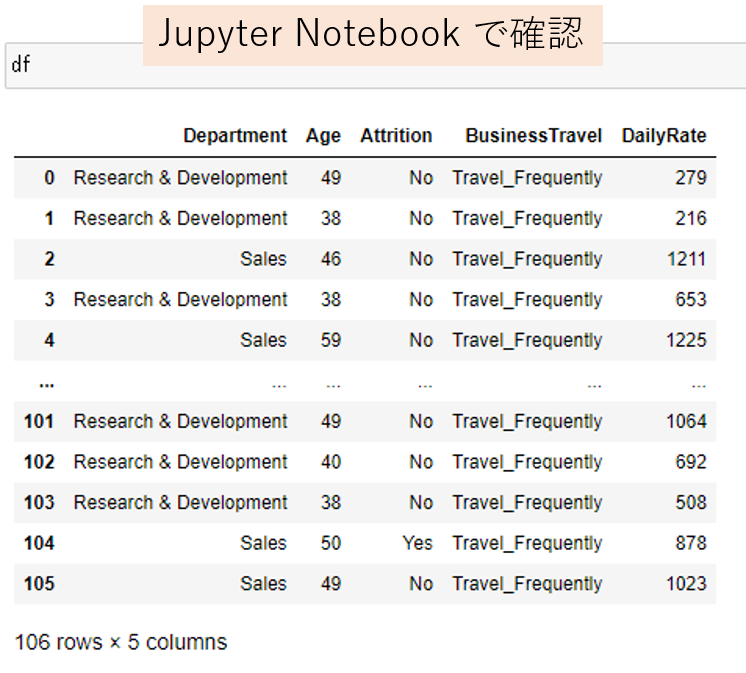
このQueryでは、抽出するカラムを"Department", "Age", "Attrition", "BusinessTravel", "DailyRate"のみを抽出しますが、それ毎に改行しています。
また、条件として、"BusinessTravel"="Travel_Frequently" かつ、"DailyRate" < 1350 かつ "Age" > 36に絞りますが、これも見やすくするため改行しています。
1
2
3
4
5
6
7
8
9
10
11
12
query = """
SELECT
"Department",
"Age",
"Attrition",
"BusinessTravel",
"DailyRate"
FROM "HR_Employee_Attrition_tab"
WHERE "BusinessTravel"="Travel_Frequently"
AND "DailyRate" < 1350
AND "Age" > 36
"""
このQuery を実行するコードは以下のとおりです。 すでに、DB名はdbname = "HR_Employee_Attrition.db"で定義していますので
その部分は省略していますので、注意してください。
1
2
3
4
5
conn = sqlite3.connect(dbname)
cur = conn.cursor()
# 変数Queryで定義したSQL 文を使ってpandas Dataframeで読み出す。
df = pd.read_sql(query, conn)
内容を確認します。
[ここがポイント!]sqlite3 モジュールで作成したDBは、DB Browser for SQLiteから操作可能です。SQL文の練習には、Python 上のsqlite3を使うだけでなく、DB Browser for SQLiteを使ってみるのも、環境のセットアップ等を考えると効率的に行えます。sqlite3と一緒にDB Browser for SQLiteをPCにインストールして一緒に遊んでみるのも、いいかもしれません
参照ページ一覧
このブログを作成するにあたり、以下のページを参考にしています。併せてご覧ください。
1) サンプルデータセットの説明
2) UnicodeDecodeErrorで csv ファイルが読み込みエラーになる
3) DB Browser for SQLite