
データフレームをJupyter Notebook で操作するにあたり、データセットをそのままのサイズでは操作せず、関連のある列だけを取捨選択、再配置して使うことが多いと思います。 実際のところ、列名を指定して再配置より、列番号を指定して再配置する方が簡単なため、私はもっぱら列番号指定を使っています。今回は、備忘録を兼ねて以下のデータフレーム操作の前段階についてBlogにまとめました。
- Jupyter Notebook の表示を画面一杯にする
- 列名指定と列番号指定のPros and Cons
- 列番号と列名参照用のデータフレームの作成と表示
- サンプルコードとイメージ画像
サンプルデータセット
EXCELの達人からPythonの達人へ:住民基本台帳年齢階級別人口から都道府県別人口を作成するで紹介している【総計】令和3年住民基本台帳年齢階級別人口(都道府県別)の人口データを例に説明します。
具体的なRead CSVファイルのCodeは以下のとおりです。 本サイトのUnicodeDecodeErrorで csv ファイルが読み込みエラーになるでこのCodeについてBlog があります。 ご参考になれば幸いです。
1
2
3
import codecs
with codecs.open("2108nsnen_2.csv", mode ="r", encoding ="utf-8", errors="ignore") as file:
df = pd.read_csv(file, delimiter =",", header=0)
データフレームの再配置
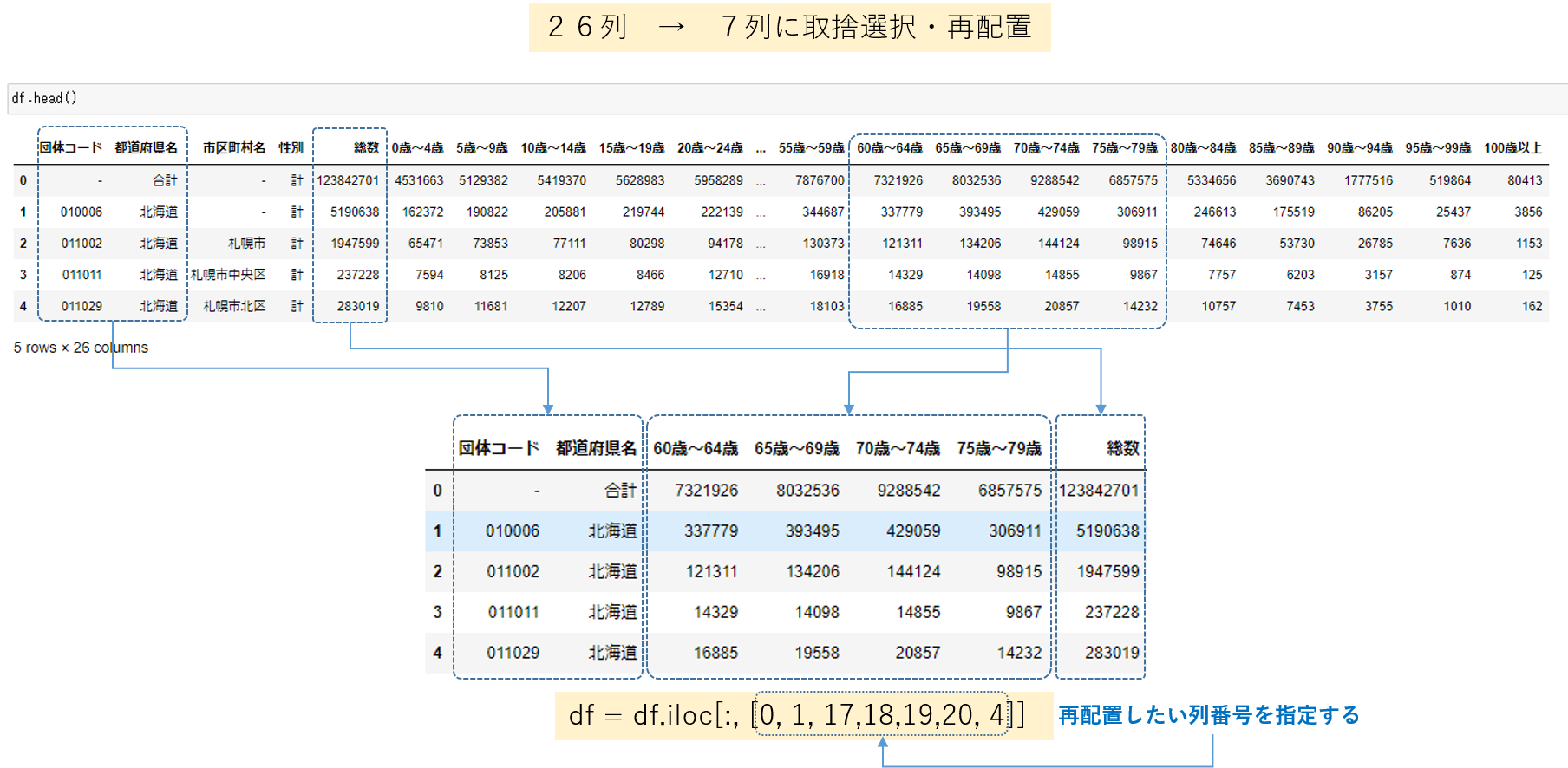
Jupyter Notebook の作業域を画面いっぱいにしたとしても、今回のデータセットのように26列もあるとdf.head()の表示には、以下のような問題があります。
- 列名の前後10列ぐらいしか表示されないため、列名と列番号をJupyter Notebook から確認できない
- すべての列が表示されたとしても、列番号は表示されないため数える必要がある
今回は、表示された列の再配置ですので、列名を指定すれば再配置は可能ですが、列名を再配置する列分、指定します。 メリットとしては、どの列を再配置したかコードだけでわかります。 一方、対応する列番号が分かれば列番号を指定するだけですので、再配置する列が多ければ、多いほどメリットを感じると思います。 デメリットは、どの列を再配置したかはdf.head()等のコマンドの結果から確かめる必要があります。
1
2
3
4
5
#方法1 *列名の指定*
df = df[["団体コード", "都道府県名", "60歳~64歳", "65歳~69歳", "70歳~74歳", "75歳~79歳", "総数" ]]
#方法2 *列番号の指定*
df = df.iloc[:, [0, 1, 17,18,19,20, 4]]
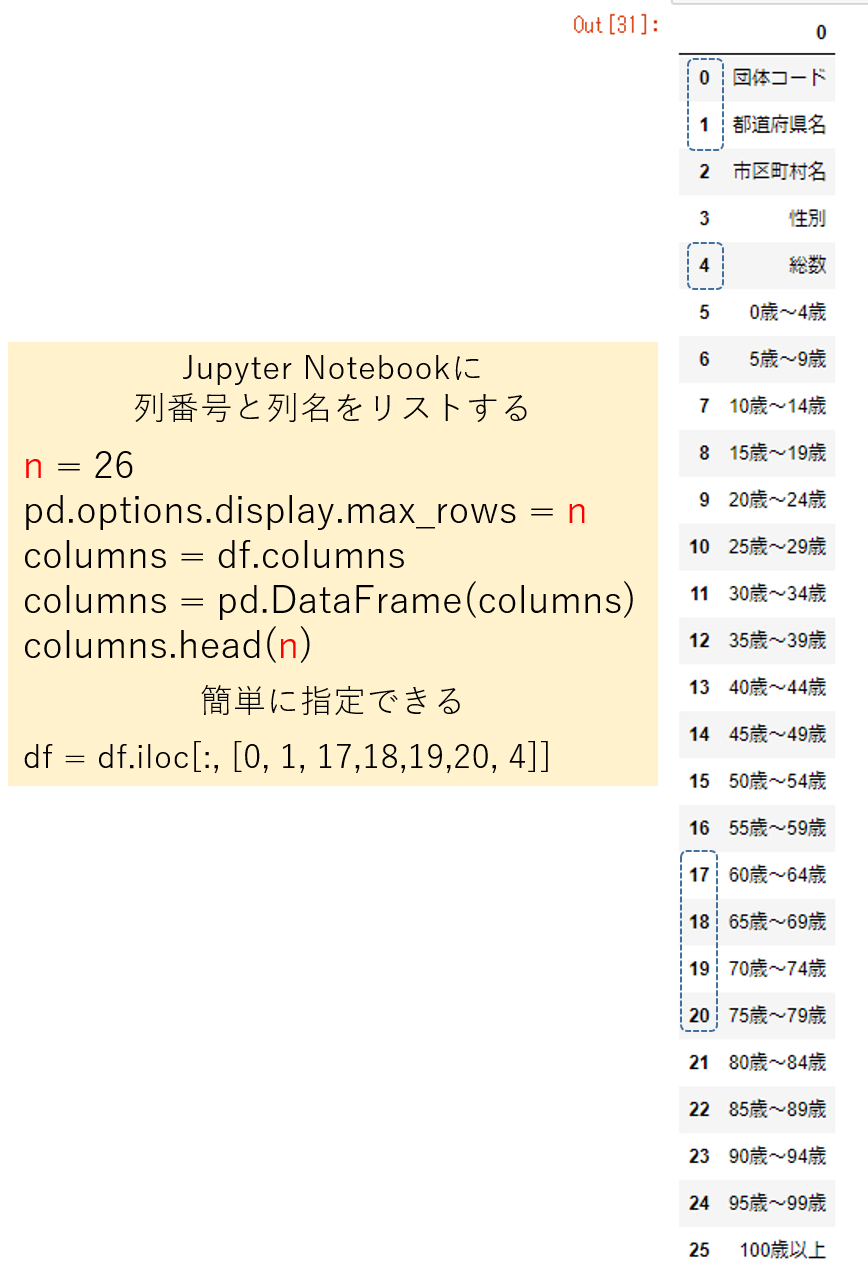
方法2 で再配置するためにすべての列をデータフレームにして、列数分の行数を表示するようにします。
列番号と列名をリストするPython コード
1
2
3
4
5
6
7
import pandas as pd
n = 26
pd.options.display.max_rows = n
columns = df.columns
columns = pd.DataFrame(columns)
columns.head(n)
すべての列名を表示させる
以下がイメージになります。 インデックス値がそのままオリジナルの列番号になります。
参照ページ一覧
本ブログは、以下の本サイトの記事等を参考に作成しました。
1) EXCELの達人からPythonの達人へ:住民基本台帳年齢階級別人口から都道府県別人口を作成する
2) 【総計】令和3年住民基本台帳年齢階級別人口(都道府県別)
3) UnicodeDecodeErrorで csv ファイルが読み込みエラーになる