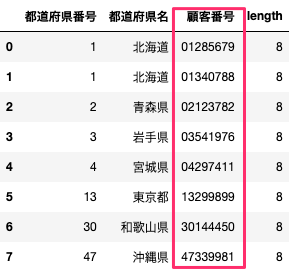
顧客番号の先頭2桁が都道府県番号のように0(ゼロ)から始まる番号のゼロが抜け落ちたリストのデータクリーニングをした際に利用したmap とzfill メソッドの使い方をブログにまとめました。基本的な内容ですが、日常的に使う場面が多いと思います。演習用にデータフレームから用意しましたのでご参考になれば幸いです。
問題の所在
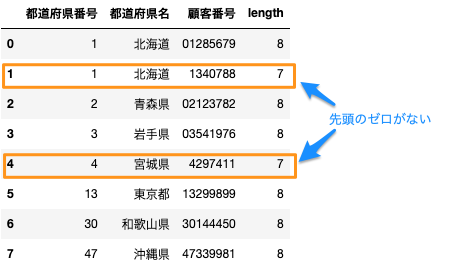
データフレームのとおり、2番目の北海道と宮城県の顧客番号数値(整数)で入力されてしまい、最初のゼロがありません。従って、文字数も7つとなってしまっています。 何も考えずに、エクセルで新規シートを作成し、手打ちで01340788と入力すると、勝手に最初のゼロが取れて1340788となってしまいます。
列の値に文字列と数値が混在してしまい、ゼロから始まる番号の0が抜け落ちたデータの修復の手順を説明します
チートシート
| やりたいこと | How To |
|---|---|
顧客番号の列の値を文字列にするlengthという列を追加して顧客番号の値の長さを求める |
df['顧客番号']=df['顧客番号'].astype(str)df['length']=list(map(len, df['顧客番号']))*値の長さを求めるには文字列のデータ型である必要あり |
| 顧客番号の列の値を変数sに代入する 顧客番号の値の長さを「8」で統一する。 「7」しかないフィールドは先頭にゼロを追加する |
s = df['顧客番号']df['顧客番号'] = pd.DataFrame(s.str.zfill(8)) |
コーディングサンプル
演習用のデータフレームを用意します。以下のコーディングをコピーしてJupyter Notebook で実行してみてください。
演習用のデータフレームを用意する
1
2
3
4
5
6
7
8
9
10
11
# 必要なモジュールをインポートします
import numpy as np
import pandas as pd
# 演習用のデータフレームを作成します。
# 2番目の北海道と宮城県の顧客番号はint型でその他はstr型でデータフレームを作成
df = pd.DataFrame({'都道府県番号': [1,1,2,3,4,13,30,47],
'都道府県名': ['北海道', '北海道', '青森県','岩手県', '宮城県', '東京都', '和歌山県', '沖縄県'],
'顧客番号': ['01285679', 1340788, '02123782', '03541976', 4297411, '13299899', '30144450', '47339981']},
index=[0, 1, 2, 3, 4, 5, 6,7])
# データフレームを表示します
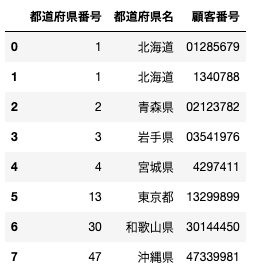
df
以下のように表示されると思います。2番目の北海道と宮城県の顧客番号数値(整数)のため最初のゼロが無い状況をシミュレーションしています。
顧客番号の文字列の長さを求める
1
2
3
4
5
6
# 顧客番号の列をstr型にして、文字列の長さ(文字数)を
# 求められるようにする
df['顧客番号']=df['顧客番号'].astype(str)
# lengthという新しい列を追加して顧客番号の長さを求める
df['length']=list(map(len, df['顧客番号']))
df
以下のように表示されると思います。lengthという新しい列を追加され顧客番号の長さが示されています。
顧客番号の長さを均一にする
1
2
3
4
5
6
# 顧客番号を変数sに代入する
s = df['顧客番号']
# 顧客番号の値の長さを「8」で統一する。
# 「7」しかないフィールドは先頭にゼロを追加する
df['顧客番号'] = pd.DataFrame(s.str.zfill(8))
df
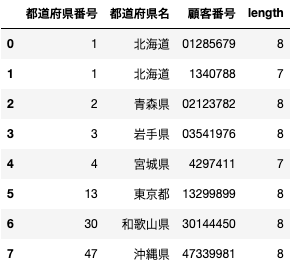
以下のように表示されると思います。赤枠で示しているとおり
顧客番号の長さが「8」に統一され、7つしかない行の顧客番号のところには左詰で0が埋められています。