
クロス集計表とヒートマップ
クロス集計表とは、2つのカテゴリーに属するデータを各々のカテゴリーで分類して、それぞれのカテゴリーに交わるセルにその度数(サンプル数、頻度)を集計した表のことです。クロス集計表では度数は数字で表していますが、その数字の大小を色の濃淡で視覚的に表現するヒートマップの形にすると今まで見えていなかったものが見えたりします。
クロス集計表のサンプルとして、今回使うKaggleデータのうち、男女(Gender)の列と仕事満足度(JobSatisfaction)の列の2軸でクロス集計してみました。

Pandasを使えば、簡単にクロス集計表やヒートマップを作成、描画が可能です。このブログではKaggle のHRデータの年齢とMonthly Salary のデータでクロス集計表とヒートマップの作成をご紹介したいと思います。
利用したデータセットについて サンプルデータセットについての記事でデータセットの概要を紹介しています。併せて参考にしてください。
度数分布グラフを作成する
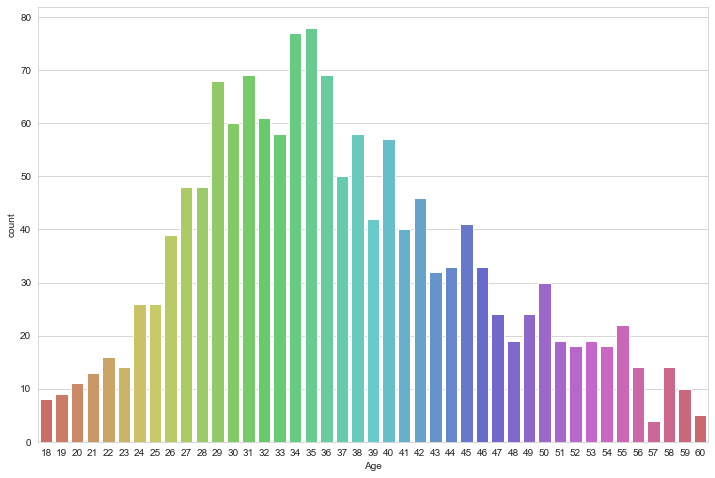
クロス集計する二つのカテゴリーとして”Age”と”MonthlyIncome”で集計したいと思います。集計にあたり、”Age” と”MonthlyIncome” 各々の度数分布を棒グラフで確認します。
seabornを使えば、簡単にきれいな度数分布グラフを作成することができます。 カラーパレットpalette='hls' で各棒(bar)に色をつけてメリハリをつけてみました。
1
2
3
4
# カレントディレクトリからKaggleデータ data.csv を読み込みます
df = pd.read_csv('/data.csv', delimiter =",", header=0)
# 年齢別の度数分布を作成します
sns.countplot(x='Age', data=df, palette='hls')
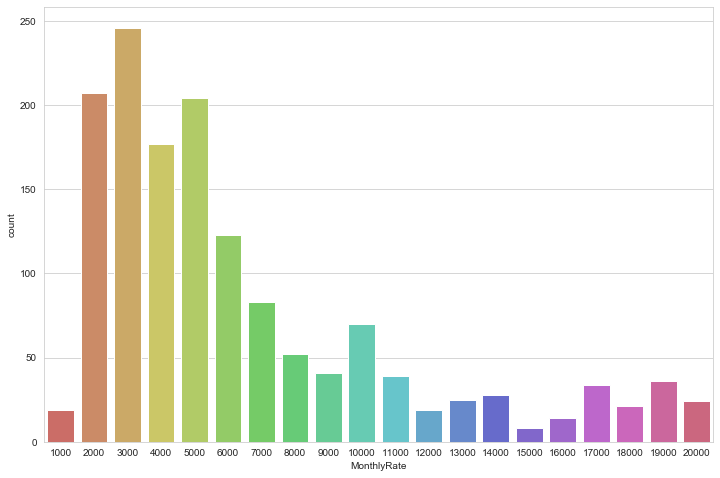
”MonthlyIncome”は1ドル単位までデータとしてあります。これでは、度数分布としては細か過ぎますので、roundメソッド.round(-3) として1,000ドル単位のレンジにして、新しい列名”MonthlyRate”を作成します。
1
2
3
4
# 1,000ドル単位に下3桁で切り捨てて、それを列名'MonthlyRateに格納します
df['MonthlyRate'] = df['MonthlyIncome'].round(-3)
# MonthlyRateの度数分布を作成します
sns.countplot(x='MonthlyRate', data=df, palette='hls')
クロス集計表を作成する
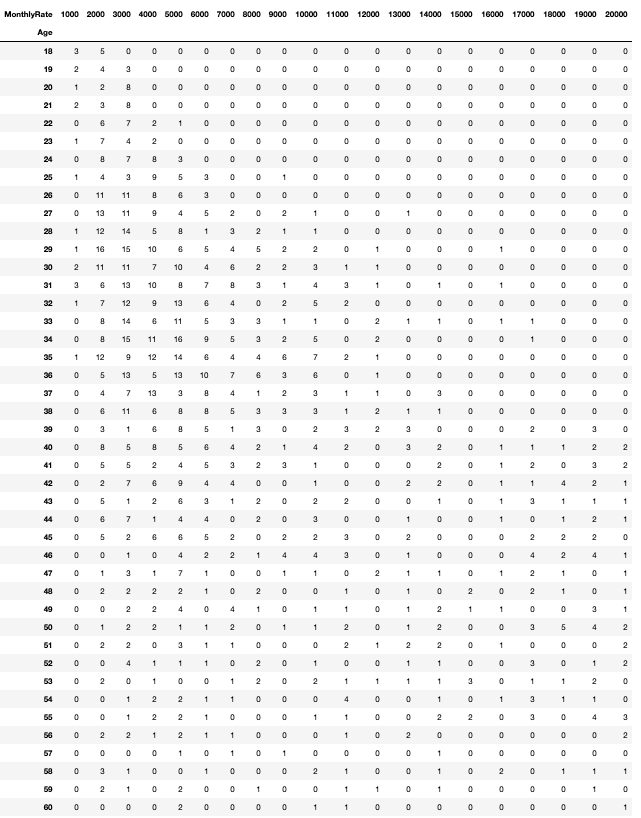
集計する2つの列の値が整数やカテゴリカルデータであれば、クロス集計表はとても簡単に作成できます。 18歳から60歳までのそれぞれの年齢ごとの、月額給与が1,000ドル以上から20,000ドル以上までのクロス集計表を作成します。 この集計表の表のサイズは、43 x 20 になります。 Pandas では、以下のように指定します。
1
2
ct = pd.crosstab(df['Age'], df['MonthlyRate'])
ct
結果は、以下のようになります。
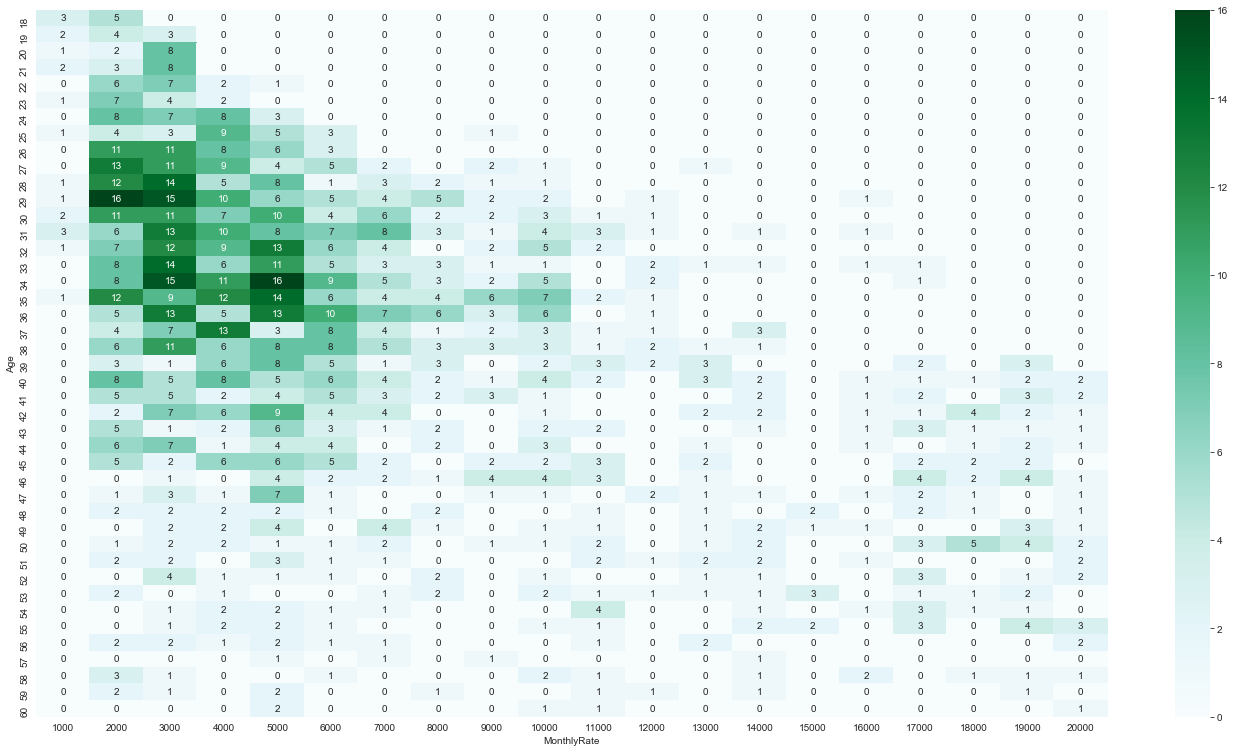
ヒートマップで大小を可視化する
それぞれのセルの大小関係を可視化するため、ヒートマップで色の濃淡で大小関係を見るとことにします。ヒートマップは今回のように表のサイズが大きい場合に特に有効な方法といえます。
1
2
3
4
5
6
7
8
9
# figsizeを変更するモジュール rcParsmsを読み込みます
from pylab import rcParams
# figsize を24 x 13インチにします
rcParams['figure.figsize'] = 24,13
# クロス集計表のデータフレーム ct のヒートマップを作成します。
# 色だけでなく、度数も表示するため、annot = True を指定します
sns.heatmap(ct, annot=True, cmap='BuGn')
# カレントディレクトリにヒートマップ図をimg_hr.pngとして保存します
plt.savefig("img_hr.png")
列ごとまたは行ごとに正規化して比率で比較する
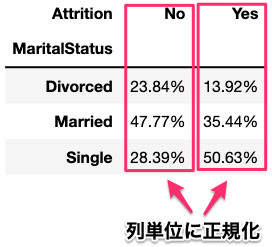
normalize = 'columns' とすると、列ごとに0~1までに正規化(normalize)します。また、小数点以下2桁でパーセント表示したい場合は、ct2.style.format("{:.2%}") とします。 ここでは、婚姻状況(MaritalStatus)と退職状況(Attrition)で見てみたいと思います。 まずは、列ごとに正規化します。
1
2
ct = pd.crosstab(df['MaritalStatus'], df['Attrition'], normalize = 'columns')
ct.style.format("{:.2%}")
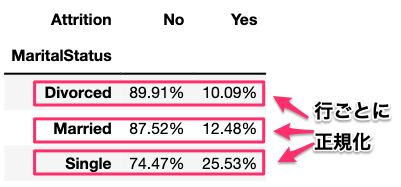
行単位で正規化したい場合は、normalize = 'index'とすればいいだけです。
ct = pd.crosstab(df['MaritalStatus'], df['Attrition'], normalize = 'index')
ct.style.format("{:.2%}")
ひとこと
データの分析の前準備としてデータの特徴や傾向、NaNや外れ値の有無の確認、データセットの理解はとても大切な作業です。データセットの理解はしばしば近視眼的にデータの型やNaNの処理をするデータセットを分析用に整えることばかりに集中しがちです。
クロス集計表、ヒートマップはデータの特徴、傾向を俯瞰してみることができて、この段階である程度の傾向値が見えてくることがしばしばあります。是非、これらを使いこなしてかっこよくまとめたいですね。