
日付データYYYY-MM-DDの最初の7桁YYYY-MMでデータセットをgroupbyで集約します。 集約の演算は合計としています。
ラベルでインデックスしてplt.barで棒グラフ化するの記事で紹介したデータフレームdf_monthを作成しながら、データ集約を説明します。
チートシート
| やりたいこと | コーディング |
|---|---|
| n桁の文字でsum()集約する さらに列名変更と再インデクスする |
df.groupby(df['Date'].str[:n]).sum() .reset_index().rename(columns={'Date' : 'New_Date'}) |
| Dateオブジェクトを文字列オブジェクトに変える | df['Date']=df['Date'].astype(str) |
今回使うデータのポイント
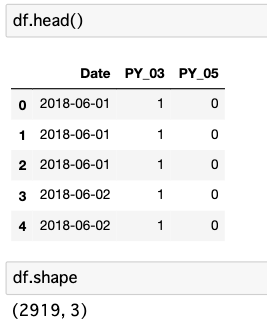
- df.shape => 2919x 3
Date列にYYYY-MM-DDの日付情報があるPY_03は一回目のトライ成功=1 まはた不成功=0PY_05に二回目のトライ成功=1 まはた不成功=0- 最初の7桁
YYYY-MMが同じもの同士で集約して他の列のPY_03,PY_05の列のそれぞれの値の合計を計算する
サンプルデータセットについての記事で紹介しているオリジナルデータです。
ラベルでインデックスしてplt.barで棒グラフ化するのデータフレームdf_monthを作成します。
元のデータセットのdf.head()とdf.shape は以下のとおりです。
アトリビュートエラーに注意
データセットの読み込む際のデータの型やDate列を計算によっては、データの型がdatetime64[ns]のままの場合があります。 そのまま、groupbyの操作をしようとすると、以下のようなエラーに遭遇します。 その場合は、データの方をstringにすれば解決します。
AttributeError: Can only use .str accessor with string values, which use np.object_ dtype in pandas
サンプルオペレーション
デフォルトの0から始まるインデックスをラベルインデックスに変更します。
1
2
# データの型を確認する
df.dtypes
問題なさそうです。 Dateの行がdatetime64[ns]だと、df['Date']=df['Date'].astype(str)が必要です。
Date object
PY_03 int64
PY_05 int64
dtype: objectgroupbyでsum集約します。ついでに、集約した列名もYear of Monthとし、更に再インデックス化します。
また、その結果はdf_monthというデータフレームに代入し、そのデータフレームの行数、列数をとります(df.shapeします)
1
2
3
# 先頭7桁の文字単位にデータフレームをsum()集約、列名も変更し再インデクス化する
df_month=df.groupby(df['Date'].str[:7]).sum().reset_index().rename(columns={'Date': 'Year of Month'})
df_month.shape
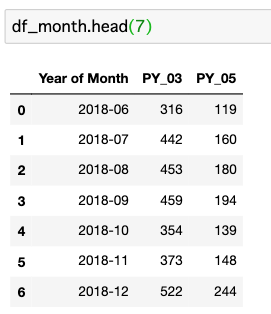
以下のとおり、7行に集約されました。
(7, 3)7行なので、データフレームすべてを表示しましょう。
可視化の記事ラベルでインデックスしてplt.barで棒グラフ化するも一緒に御覧ください。
ひとこと
groupbyはデータの集約化ではなくてはならないメソッドです。列の一部を共通項として集約もよく行う集約方法になります。集約する列が文字列とし扱う場合は、アトリビュートエラーに注意しましょう。