
カテゴリカル変数の中身を要約し、理解を深めます。 要約とは、要素の総数の把握から、集約化、グラフ等の可視化で各列のイメージを持つことです。
チートシート
| やりたいこと | コーディング |
|---|---|
| '列' のカテゴリ変数の値をカウントする(重複は除く) | df['列名'].value_counts() |
| 要約された統計量をみる | df['列名'].describe() |
| ヒストグラムを作図する | sb.countplot(x='列名', data=df, palette='hls') |
- そもそもデータタイプがカテゴリカル変数かどうか
- カテゴリカルデータの要素を概観する
- 総数
- 種類
- 種類ごとの数(集計)
- NAN(欠損値)の有無を調べる
2の 「カテゴリカルデータの要素を概観する」について説明します。
今回もオリジナルデータを使用します。 サンプルデータセットについてにデータセットの概要があります。参考にしてください。
データを概観する
カテゴリカル変数では、df.dtypes と入力すれば、各列にどんなデータ型で格納されているかわかります。
本サイトで使うデータセットはデータフレーム化され pandasで扱えるようになっていますが、データフレームdf の、列名PY_07 に都道府県番号が入っています。まず、読み込んだデータフレームでPY_07はどのようなデータ型で認識されているか確認します。
1
2
# PY_07 のデータの型の確認
df['PY_07'].dtypes
結果は以下のとおりです。この列を使えば、47都道府県ごとに他の列のデータの中身を分類できます。
CategoricalDtype(categories=[ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15,
16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30,
31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45,
46, 47],
ordered=False)各都道府県番号ごとの要素の数(度数)を見るには、df['列名'].value_counts()を使います。
データセットの中身を都道府県別に、集約して差異を見てみます。
1
df['PY_07'].value_counts()
結果は以下のとおり:
13 1114
27 691
23 50
<省略>
39 41
36 38
5 33
41 15
29 10
Name: PY_07, dtype: int64describe メソッドで基本的な統計量を確認します。
df['列名'].describe()
1
2
# カテゴリカル変数の列の基本統計量を確認します
df['PY_07'].describe()
結果は以下のとおり:
count 7507
unique 47
top 13
freq 1114
Name: PY_07, dtype: int64これで、総度数(count)は、7507, 種類の総数 (unique)は、47種類。 その中は、「13(東京都)」 で、その数=最頻値 (freq) は、1114個であることがわかりました。 次に、棒グラフで各県の様子を見てみます。 棒グラフはプレゼン等でビジュアルで説明する際にとても有効です。
1
2
3
4
# 度数分布図をseaboan 書く
import seaborn as sb
sb.set_style('whitegrid')
sb.countplot(x='PY_07', data=df, palette='pastel')
棒グラフ:
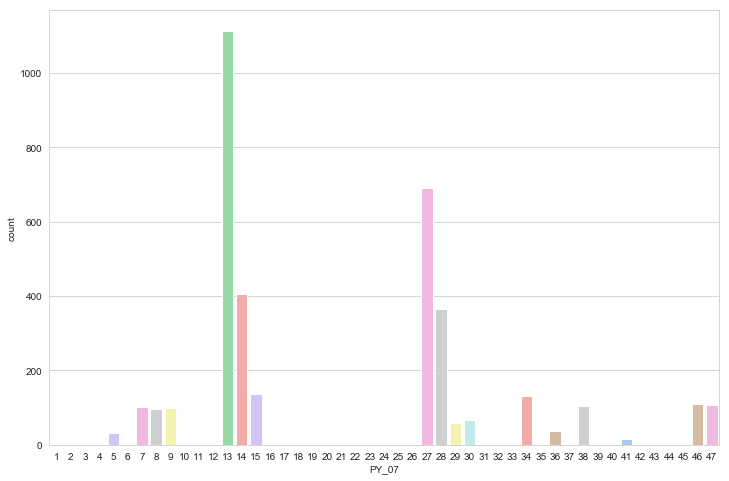
ひとこと
解析するデータの中身によるが、私の経験では連続(温度や比率等のどんな値でも取りうる)データよりカテゴリカル(尺度や種類を表す)データの方が圧倒的に多いと感じています。 カテゴリカル変数には性別、県番号、業種、評価等、枚挙にいとまがありません。 カテゴリカル変数のデータは、説明変数として使う場合は、「ダミー変数化」します。 目的変数として使う場合は、分類問題のモデルで解析します。 これらもの使い方もこのサイトで説明します。